HTTP status codes look straightforward until an alert fires and the number doesn’t tell the full story. A site returns a 200 but users see errors. A 500 shows up briefly and disappears before you can reproduce it. Misreading these codes slows triage and leads to the wrong fix.
This guide breaks down HTTP status codes with an operator’s mindset. It explains what each class means, how they show up in real monitoring data, and where teams often misinterpret them during incidents.
You’ll learn how to map status codes to actual failure modes, decide when a response is actionable, and use them to speed up troubleshooting instead of adding noise. If HTTP codes drive your alerts, this is how to read them properly.
Decoding HTTP status codes
HTTP status codes, typically a sequence of three numbers, are a reply from the server in response to a request made by a web browser.
A common example many might recognize is the 404 error, which signals that a particular page could not be found — a type of HTTP client error.

These codes (known as response status codes) facilitate the communication process between an internet browser and the server. They are categorized into various classes, with each class defined by the first digit in the code.
When using website monitoring, you get these HTTP statuses in alerts (based on your settings).
For example, codes starting with ‘4’, like the 404 error, are used for issues relating to the accessibility or availability of a page or site. On the other hand, a code beginning with ‘2’ typically indicates that the browser’s request was processed successfully.
| Status code | What it means |
| 1xx Informational response | |
| 100 | Continue |
| 101 | Switching protocols |
| 102 | Processing |
| 103 | Early Hints |
| 2xx Succes | |
| 200 | OK |
| 201 | Created |
| 202 | Accepted |
| 203 | Non-Authoritative Information |
| 204 | No Content |
| 205 | Reset Content |
| 206 | Partial Content |
| 207 | Multi-Status |
| 208 | Already Reported |
| 226 | IM Used |
| 3xx Redirection | |
| 300 | Multiple Choices |
| 301 | Moved Permanently |
| 302 | Found (Previously “Moved Temporarily”) |
| 303 | See Other |
| 304 | Not Modified |
| 305 | Use Proxy |
| 306 | Switch Proxy |
| 307 | Temporary Redirect |
| 308 | Permanent Redirect |
| 4xx Client Error | |
| 400 | Bad Request |
| 401 | Unauthorized |
| 402 | Payment Required |
| 403 | Forbidden |
| 404 | Not Found |
| 405 | Method Not Allowed |
| 406 | Not Acceptable |
| 407 | Proxy Authentication Required |
| 408 | Request Timeout |
| 409 | Conflict |
| 410 | Gone |
| 411 | Length Required |
| 412 | Precondition Failed |
| 413 | Payload Too Large |
| 414 | URI Too Long |
| 415 | Unsupported Media Type |
| 416 | Range Not Satisfiable |
| 417 | Expectation Failed |
| 418 | I’m a Teapot |
| 421 | Misdirected Request |
| 422 | Unprocessable Entity |
| 423 | Locked |
| 424 | Failed Dependency |
| 425 | Too Early |
| 426 | Upgrade Required |
| 428 | Precondition Required |
| 429 | Too Many Requests |
| 431 | Request Header Fields Too Large |
| 451 | Unavailable For Legal Reasons |
| 5xx Server Error | |
| 500 | Internal Server Error |
| 501 | Not Implemented |
| 502 | Bad Gateway |
| 503 | Service Unavailable |
| 504 | Gateway Timeout |
| 505 | HTTP Version Not Supported |
| 506 | Variant Also Negotiates |
| 507 | Insufficient Storage |
| 508 | Loop Detected |
| 510 | Not Extended |
| 511 | Network Authentication Required |
Deciphering the HTTP status code directory
HTTP status codes might seem like a secret language, but they’re quite logical. Let’s decode the classes.
Class 1XX: the informational codes
What is 100 continue?
This preliminary response indicates that everything so far is okay, and that the client should proceed with the request or ignore it if it’s already finished.
What is 101 continue?
This code is sent in response to an upgrade request header from the client, and the server is switching the protocols according to the requester’s instructions. For example, the server might switch from HTTP 1.1 to HTTP 2.
What is 103 early hints?
The server sends this code to notify the client about potential redirection targets, even before the client finishes its request. This code helps optimize loading by reducing round-trip times.
Class 2XX: codes for success
- 200 OK
- 201 Created
- 202 Accepted
- 203 Non-Authoritative Information
- 204 No Content
- 205 Reset Content
- 206 Partial Content
What is 200 OK?
This means the request succeeded, and the resultant entity body contains the requested resource. It’s the standard response for successful HTTP requests.
What is 201 created?
A new resource was successfully created in response to the request. This is typically the response sent after POST requests or some PUT requests.
What is 202 accepted?
Seeing this means the request has been accepted for processing, but the server has not yet completed the processing.
What is 203 non-authoritative information?
The server successfully processed the request, but is returning a cache or proxy response.
What is 204 no content?
The server successfully processed the request and isn’t returning any content. This status is often used for DELETE requests where returning a body with the status of the deleted element is not necessary.
What is 205 reset content?
The server processed the request, and the user agent should reset the document view. This could be used when the server has fulfilled the request and desires that the user agent reset the GUI.
What is 206 partial content?
The server is delivering a part of the requested resource due to a range header sent by the client. For instance, if you’re downloading a large file, the server might send the file in smaller parts rather than all at once.
Class 3XX: the redirection codes
- 300 Multiple Choices
- 301 Moved Permanently
- 302 Found
- 303 See Other
- 304 Not Modified
- 307 Temporary Redirect
- 308 Permanent Redirect
TIP: Catch redirects and get alerts with UptimeRobot using the new “Don’t follow redirects” option.
What is 300 multiple choices?
The server has several actions to choose from, depending on the client. For example, there might be different file formats or languages to pick.
What is 301 moved permanently and how to fix it
This code means the requested resource has moved to another location permanently. Links to the old URL are automatically redirected to the new URL.
How to fix it:
- Update your internal links to point to the new URL.
- Be sure that any external links to your site are updated to the new URL.
Implement a 301 redirect on your server to automatically redirect traffic from the old URL to the new URL.
What is 302 found and how to fix it
This response code means that the URI of the requested resource has been temporarily changed. However, future requests should still use the original URI.
How to fix it:
- Make sure the correct URI is being used for temporary redirects.
- Update your server configurations to reflect the correct temporary redirect settings.
- Test the redirect to confirm it points to the temporary location.
What is 303 see other and how to fix it
The server sends this response to direct the client to another URL. This status code is commonly used to redirect after a PUT or POST request.
How to fix it:
- Check to see that the server is correctly configured to handle the redirection.
- Verify that the URL provided in the response is correct.
- Update client applications to handle the 303 status code appropriately.
What is 304 not modified?
This tells the browser that the requested resource has not been modified since it was last loaded, and/or the client can use a cached version of the resource.
What is 307 temporary redirect and how to fix it
The requested resource has been temporarily moved to a different URL. Unlike the 302 Found status code, the 307 code explicitly states that the HTTP method should not change when the redirected request is made.
This means that if a POST request was initially sent, the redirected request should also be a POST.
How to fix it:
- Verify the correct temporary URL
- Ensure that the temporary URL is correctly set in your server’s configuration file or redirect rules.
- Confirm that the resource should indeed be temporarily moved and not permanently. If the move is permanent, consider using a 301 status code instead.
What is 308 permanent redirect and how to fix it
This is similar to a 301, but it means that all future requests should repeat the original request using the new URL.
Unlike a 301 redirect, the 308 status code ensures that the HTTP method and the body of the original request are preserved when the redirected request is made.
This means that if the original request was a POST, the redirected request will also be a POST.
How to fix it:
- Update any hardcoded links to the new URL.
- Implement server-side 308 redirects for all relevant URLs.
- Inform users and partners of the permanent change in URL.
- Update external links and references.
- Watch web traffic to make sure that it’s working.
Class 4XX: the client error codes
- 400 Bad Request
- 401 Unauthorized
- 402 Payment Required
- 403 Forbidden
- 404 Not Found
- 405 Method Not Allowed
- 406 Not Acceptable
- 407 Proxy Authentication Required
- 408 Request Timeout
- 409 Conflict
- 410 Gone
- 411 Length Required
- 412 Precondition Failed
- 413 Payload Too Large
- 414 URI Too Long
- 415 Unsupported Media Type
- 416 Range Not Satisfiable
- 417 Expectation Failed
- 418 I’m a teapot
- 422 Unprocessable Entity
- 425 Too Early
- 426 Upgrade Required
- 428 Precondition Required
- 429 Too Many Requests
- 431 Request Header Fields Too Large
- 451 Unavailable For Legal Reasons
- 499 Client Closed Request
What is 400 bad request and how to fix it
The 400 Bad Request status code indicates that the server could not understand the request due to malformed syntax. This error is a client-side issue, meaning the request sent by the client (a web browser, for instance) is incorrect or corrupt and the server can’t process it.
How to fix it:
- Validate the request syntax and ensure it conforms to the server’s expectations.
- Correct any formatting issues in the request payload.
- Use debugging tools to identify and fix the source of the malformed request.
- Clear browser cache and cookies.
- Check for a too large request size.
What is 401 unauthorized and how to fix it
The 401 Unauthorized status code indicates that the request has not been applied because it lacks valid authentication credentials for the target resource.
Essentially, the server is refusing to fulfill the request until the client provides proper authentication.
How to fix it:
- Verify that the correct authentication credentials are being used.
- Check to see if the user has the necessary permissions to access the resource.
- Implement proper authentication mechanisms on the server.
- Check for configuration issues.
- Look at server logs for more information.
What is 402 payment required?
Reserved for future use, this code was originally intended to signal that the client must pay to access the requested resource.
As of now, it is not actively used in HTTP/1.1 but was envisioned as a mechanism to support digital payment systems.
What is 403 forbidden and how to fix it
The 403 forbidden status code indicates that the server understands the request but refuses to authorize it. Unlike the 401 unauthorized status, providing authentication credentials will not resolve this issue.
The request is simply not permitted, regardless of the user’s identity.
How to fix it:
- Verify that the client has the necessary permissions to access the resource.
- Check the server’s access control settings to make sure they’re correct.
- If necessary, update the permissions to allow access.
What is 404 not found and how to fix it
This means the server can’t find the requested resource. Links that lead to a 404 page are often called broken or dead links.
How to fix it:
- Verify the URL for any typos or errors.
- Check to see that the resource exists at the specified URL.
- Create a custom 404 page to guide users to other useful content on your site.
What is 405 method not allowed and how to fix it
The HTTP method used in the request is not supported for the resource identified by the request URL.
This means that the server recognizes the request method, but the target resource doesn’t support that method.
How to fix it:
- Check the allowed HTTP methods for the resource.
- Ensure the client uses a valid method (like GET, POST) for the resource.
- Update the server configuration to support the required method, if applicable.
What is 406 not acceptable and how to fix it
The server cannot produce a response that matches the list of acceptable formats specified by the client in the request headers.
It basically means that the server is unable to generate a response in a format that is acceptable to the client.
How to fix it:
- Verify that the client’s request headers specify acceptable formats.
- Make sure the server can generate a response in one of the acceptable formats.
- Update the server configuration to handle the requested content type.
What is 407 proxy authentication required and how to fix it
The 407 status code means the client must authenticate itself with the proxy before the request can be forwarded to the server.
How to fix it:
- Verify that the client provides the correct authentication credentials for the proxy.
- Make sure the proxy server is configured to accept and process the authentication.
- Check the proxy settings to ensure they allow forwarding to the target server.
What is 408 request timeout and how to fix it
The server didn’t receive a complete request from the client within the required time. This is often due to network issues or the client taking too long to send the request.
How to fix it:
- Check the network connection to see its stability.
- Use network diagnostic tools to identify and resolve any connectivity issues.
- Optimize the client’s request to send data more quickly.
- Reduce the size of the request payload if possible so it can be transmitted within the server’s timeout window.
- Increase the server’s timeout settings if necessary.
What is 409 conflict and how to fix it
The request couldn’t be processed because of a conflict in the request, such as an edit conflict in the case of multiple updates being made simultaneously to the same resource.
How to fix it:
- Review the request to identify the source of the conflict.
- Ensure that no other operations are causing conflicts with the current request.
- Resolve any data inconsistencies that may be causing the conflict.
- Merge conflicting changes if possible, or choose which changes to prioritize.
- Communicate with other users or processes involved in the conflict to coordinate changes.
What is 410 gone and how to fix it
Simply, the requested resource is no longer available and will not be available again.
How to fix it:
- Verify that the resource is indeed gone and not available under a different URL.
- Update or remove any links pointing to the resource to avoid broken links.
- Implement a custom 410 page to inform users that the resource is no longer available.
What is 411 length required and how to fix it
This happens when the server refuses to accept the request without a defined Content-Length.
How to fix it:
- Ensure the client includes a valid Content-Length header in the request.
- Verify that the Content-Length header value matches the actual length of the request body.
- Update the client application to automatically include the Content-Length header for requests that require it.
What is 412 precondition failed and how to fix it
The server does not meet one of the preconditions that the requester put on the request. Preconditions are set by the client so the server processes the request only if specific conditions are met.
This is often used to prevent accidental overwrites or to make sure resources have not been modified since the client last interacted with them.
How to fix it:
- Review the preconditions specified in the request headers.
- Identify the specific preconditions in the request headers such as If-Match, If-None-Match, If-Modified-Since, and If-Unmodified-Since.
- See that the server can meet these preconditions or adjust the request to align with the server’s capabilities.
- Update the client application to handle precondition failures gracefully.
- Provide feedback to users or retry the request with updated preconditions.
What is 413 payload too large and how to fix it
The request is larger than the server is willing or able to process. This commonly occurs when a client attempts to upload a file or send data that exceeds the server’s capacity or predefined limits.
How to fix it:
- Reduce the size of the request payload.
- Increase the server’s maximum allowed payload size if possible.
- Use file compression or chunked transfer encoding for large requests.
What is 414 URI too long and how to fix it
The URI Uniform Resource Identifier (URI) provided in the request is too long for the server to process. This error often occurs when the client’s request URI exceeds the server’s capacity, typically due to excessive query parameters or overly lengthy path segments.
How to fix it:
- Shorten the URI by reducing the number of query parameters or path segments.
- Use POST requests instead of GET requests for large amounts of data.
- Optimize the client application to generate shorter URIs.
What is 415 unsupported media type and how to fix it
The request entity has a media type that the server refuses to accept because the payload’s media type is not supported by the server or resource.
This happens when the client sends data in a format that the server cannot process.
How to fix it:
- Verify that the media type specified in the Content-Type header is supported by the server.
- Convert the request payload to a supported media type.
- Update the server configuration to handle additional media types if necessary.
What is 416 range not satisfiable and how to fix it
The client has asked for a portion of the file (specified by the Range header in the HTTP request), but the server cannot supply that portion.
This error will show if the range specified is outside the size of the target file.
How to fix it:
- Verify that the range specified in the request headers is valid. For example, if the file is 1,000 bytes and the range is set to 1,001-2,000, this range is invalid.
- Ensure the resource being requested supports range requests. Some resources or server configurations might not support range requests.
- Adjust the range request to a valid portion of the file.
What is 417 expectation failed and how to fix it
The server cannot meet the requirements of the Expect request-header field. This header is for when the client wants the server to confirm that certain conditions are met before proceeding with the request.
How to fix it:
- Review the expectations specified in the Expect header of the request. Commonly, the Expect: 100-continue header is used to check if the server can handle the request payload before sending it.
- Make sure that the server is configured to meet the expectations specified in the Expect header. If the server does not support the required expectation, it needs to be configured accordingly.
- Update the client application to handle cases where expectations cannot be met.
What is 418? I’m a teapot?
This cheeky code was defined in 1998 as one of the traditional IETF April Fools’ jokes.

What is 422 unprocessable entity and how to fix it
This means that the server understands the content type of the request entity (the syntax of the request is correct), but it was unable to process the contained instructions. This usually occurs due to semantic errors or issues in the data being sent.
How to fix it:
- Validate the request payload to ensure it meets the required schema or format.
- Correct any semantic errors in the request data.
- Implement proper error handling to provide detailed feedback to the client.
- Use tools like Postman or curl to send test requests to the server with the corrected data to ensure that the errors are resolved and the request is processed successfully.
What is 425 too early?
This shows that the server is unwilling to risk processing a request that might be replayed. This usually happens in scenarios where a client sends a request with an Expect header indicating an expectation that might lead to replaying the request, such as with early data in TLS 1.3.
The server responds with 425 to indicate that it is not willing to process the request at this time due to the risk of replay attacks.
What is 426 upgrade required and how to fix it
This status is used when the server refuses to perform the request using the current protocol and requires the client to upgrade to a specified protocol.
How to fix It:
- Verify that the client software is capable of supporting the required protocol.
- Update or configure the client to enable the necessary protocol (e.g., HTTP/2).
- Update the client’s request to include the appropriate Upgrade header.
- Check server settings and documentation to confirm support for the upgraded protocol.
What is 428 precondition required and how to fix it
The server requires the request to be conditional. This means the client must include certain conditions in the request headers, ensuring that the request is processed only if specific conditions are met.
How to fix it:
- Make the client include appropriate preconditions in the request headers. Common precondition headers include If-Match, If-Unmodified-Since, If-None-Match, and If-Modified-Since.
- Check the server’s documentation to understand which preconditions are supported and how they should be formatted.
- Adjust the request to align with the server’s requirements.
What is 429 too many requests and how to fix it
Seeing this means the user has sent too many requests in a given amount of time. This response is often used by servers to prevent abuse and overloading.
When a client exceeds the request limit, the server temporarily restricts further requests until a specified time period has passed.
How to fix it:
- Implement rate limiting on the client side to prevent excessive requests.
- Use exponential backoff or retry-after headers to manage retry attempts.
- Optimize the client application to reduce the frequency of requests.
- Lastly, communicate the rate limit to the user.
What is 431 request header fields too large and how to fix it
The server is unwilling to process the request because its header fields are too large. The server has its own limits, and your request header just needs to be within the limit to work properly.
How to fix it:
- Reduce the size of the request headers by simplifying strings, taking out any unnecessary headers, or shortening the values of headers where possible.
- Make sure the headers don’t contain unnecessary or redundant information.
- Split large headers into smaller, more manageable parts if possible.
- Or, adjust the server settings to allow for larger request headers.
What is 451 unavailable for legal reasons and how to fix it
A server operator has received a legal demand to deny access to a resource or to a set of resources that includes the requested resource.
This status code is to signify that the content has been removed or blocked due to legal reasons, such as a court order or government directive.
How to fix it:
- Review the legal demand or court order.
- Fully understand the legal implications and the specific content or resources that need to be removed or blocked.
- Remove or block the specific content as instructed by the legal demand.
- Implement any additional measures required by the legal order.
- If necessary, consult with legal professionals to understand your obligations and any potential remedies.
What is 499 client closed request?
The connection was closed by the client while the HTTP server was processing its request, making the server unable to send the HTTP header back.
This status might occur if a user navigates away from a page before it finishes loading, closes the browser tab, or if the client’s network connection drops during the request.
Class 5XX: the server error codes
- 500 Internal Server Error
- 501 Not Implemented
- 502 Bad Gateway
- 503 Service Unavailable
- 504 Gateway Timeout
- 505 HTTP Version Not Supported
- 506 Variant Also Negotiates
- 507 Insufficient Storage
- 508 Loop Detected
- 510 Not Extended
- 511 Network Authentication Required
- 599 Network Connect Timeout Error
What is 500 internal server error and how to fix it
This is a generic error message when an unexpected condition is encountered, and no specific message is suitable. Being so vague, it can be difficult to pinpoint what exactly the problem is.
How to fix it:
- Check server logs to identify the cause of the error.
- Verify server configurations and scripts for issues.
- Make sure all dependencies are correctly installed and configured.
What is 501 not implemented and how to fix it
The server either does not recognize the request method or lacks the ability to fulfill the request.
How to fix it:
- See that the request method is supported by the server by checking the proper documentation.
- Update server configurations to support the required method.
- Additionally, make sure that all necessary modules or plugins are installed.
What is 502 bad gateway and how to fix it
The server received an invalid response when acting as a gateway. This error could be due to various issues ranging from server overload, network issues, or misconfigurations.
How to fix it:
- Ensure the upstream server (the server from which the gateway or proxy server is receiving the response) is functioning correctly.
- Check the network connectivity between the servers using tools like tools like ping and traceroute.
- Update the gateway server configuration to handle responses properly by looking at the configuration files for any misconfigurations or syntax errors.
- Make sure the upstream server is not overloaded or timing out when handling requests.
- Sometimes, the issue might be temporary and resolve on its own.
What is 503 service unavailable and how to fix it
This status code means the server is currently unable to handle the request due to temporary overload or scheduled maintenance.
This is a temporary condition and implies that the server will be back online after resolving the issue.
How to fix it:
- Ensure server capacity is adequate for the current load.
- Implement load balancers or scaling solutions if necessary to distribute traffic across multiple servers.
- Schedule maintenance during low-traffic periods to lessen disruption to users.
Design and use a maintenance page to let users know about scheduled downtime.
What is 504 gateway timeout and how to fix it
The server didn’t receive a timely response from an upstream server and couldn’t complete the request.
How to fix it:
- Optimize server response time by reducing the server load.
- Verify that external resources the server relies on are responding promptly.
- Increase the timeout settings on the gateway server if necessary.
What is 505 HTTP version not supported and how to fix it
The server does not support the HTTP protocol version used in the request.
How to fix it:
- Ensure the client is using a supported HTTP version.
- Update the server to support newer HTTP versions if feasible.
- Modify client requests to use a compatible HTTP version.
What is 506 variant also negotiates and how to fix it
The server has an internal configuration error, and you may need to modify its request to resolve the ambiguity.
How to fix it:
- Review the server configuration for negotiation settings and make sure configuration is set up correctly to handle the different variants.
- Verify that the server can handle multiple content types and return the correct variant based on the client’s request and that it can distinguish between variants.
- Update the server to handle variant requests properly.
What is 507 insufficient storage and how to fix it
The server is unable to store the representation needed to complete the request.
How to fix it:
- Check that the server has enough storage space available.
- Remove unnecessary files and clean up disk space.
- Increase the storage capacity by adding more disk space or using cloud storage solutions.
What is 508 loop detected and how to fix it
The server detected an infinite loop while processing a request with “Depth: infinity”. This status indicates that the entire operation has failed.
How to fix it:
- Check the server-side scripts for any potential infinite loops.
- Ensure that the scripts have proper termination conditions to prevent endless loops.
- Verify that the client requests do not cause recursive calls that could lead to infinite loops.
- Install safeguards to detect and handle such conditions before they cause a loop.
- Modify the server settings to better handle loop detection and prevent infinite loops from causing failures.
- Use logging and monitoring tools to track and identify any loops in real-time.
What is 510 not extended and how to fix it
This code indicates that further extensions to the request are required for the server to fulfill it. For example, the client may need to provide additional authentication details or other necessary information.
How to fix it:
- Double check that all required extensions, parameters, and details are included in the request.
- Look through the server documentation or API specification to identify any missing elements.
- Modify the client application to include the necessary extensions or additional details in the request.
- Update the server settings or capabilities if necessary to support the required extensions.
What is 511 network authentication required and how to fix it
This status code means the client needs to authenticate itself to gain network access. It is most often used by network operators to intercept and display an authentication page before granting network access.
How to fix it:
- See that the client application is capable of handling network authentication requests.
- Design the client to detect and respond to authentication prompts, such as captive portal pages.
- Properly set up and configure the authentication server that will handle client authentication.
- Test the authentication process to ensure the client can authenticate and gain network access seamlessly.
- Use logging and monitoring to track authentication attempts and identify any issues that come up.
What is 599 network connect timeout error and how to fix it
A network connection to the server timed out, preventing the server from completing the request.
How to fix it:
- Check that all network connections between the client and server are stable and reliable, and there are no outages or disruptions in the network.
- Improve the server’s performance to reduce the response time. This can include optimizing server code, upgrading hardware, or balancing the load across multiple servers.
- Adjust the network timeout settings on the server and client to allow more time for the connection to be established.
What is 999 unknown error?
📍Although not an official error, HTTP 999 is used as a “catch-all” error code presented when a more specific error code is not provided by the server.
It’s commonly used by some social media sites like LinkedIn to limit or prevent web crawlers.
How to fix it:
- Determine which server or service is returning the 999 error.
- Check if the error occurs while accessing a specific website or API.
- Avoid sending too many requests in a short period, as this can trigger rate limiting or anti-crawling mechanisms.
- Sometimes, changing the User-Agent header in your requests can help bypass restrictions.
- If all else fails, contact the support team of the service you are trying to access for further assistance.
The impact of HTTP status codes on SEO
Understanding the technical side of SEO can be challenging, but it’s also crucial if you want to maximize your website’s visibility. An abundance of error codes can signal to search engines like Google that your website isn’t very reliable, which can negatively impact your site’s SEO.
Too many error codes can signal to search engines that your website isn’t very reliable, which can negatively impact your site’s SEO. According to Search Engine Watch, several HTTP status codes are especially critical to SEO:
302 – This temporary redirect code tells search engines generally that the original URL will eventually be restored, so the page index is never updated for better SEO.
404 – When search engine crawlers can’t access your content, your SEO suffers.
410 – This error causes search engines to remove the page from the index immediately. This means that the page will no longer appear in search engine results.
500 – Google also doesn’t like it when servers are down, so this error can negatively affect your rankings.
503 – Search engines don’t like to see “service unavailable,” and if the error keeps happening, the search engine might de-index the page, affecting your rankings.
Correct usage of HTTP status codes can help preserve your website’s SEO. For example, Google likes to see 301 permanent redirects for pages that are no longer available, allowing your site to retain its SEO value.
200 HTTP codes are also great to see — it means everything is working as it should, and Google loves you.

How to find the status code of a page
Understanding the status code of a web page is absolutely necessary for website administrators, developers, and SEO specialists.
Using browser developer tools
One of the most straightforward methods to find the status code of a web page is by using developer tools in modern web browsers. For example, in Google Chrome:
- Right-click on a webpage and select “Inspect.”
- Navigate to the “Network” tab.
- Reload the page, and a list of all requests made by the page is displayed. The first item, typically representing the page itself, will show the status code (e.g., 200 status code for a successful load).
Using online tools and API services
For a more automated approach, many online tools and API services offer the functionality to check status codes in bulk.
Websites like HTTPStatus.io allow users to enter a URL and receive the status code without needing any technical know-how. This method is great for non-developers or those conducting SEO audits.
On the more technical end, APIs such as the one provided by HTTPstatus.io offer a programmatic way to check status codes, ideal for integrating into continuous integration pipelines or for monitoring website health.
How to turn HTTP status codes into actionable alerts
HTTP status codes are only useful if you decide what to do with them. Treating every non-200 as “down” creates noise. Ignoring them hides real failures. The value sits in mapping codes to intent.
Start by separating availability from correctness. A 500-level response usually means the service failed to handle a valid request. That is an outage signal. A 400-level response means the server responded, but rejected the request. That often points to client behavior, auth issues, or bad inputs, not downtime.
Redirects deserve their own rules. A single 301 or 302 is normal. Chains, loops, or sudden changes often are not. If a monitored endpoint flips from 200 to 302 unexpectedly, something changed in routing, auth, or CDN config. That is worth investigating, even if users still land somewhere.
401 and 403 responses need context. If a public endpoint starts returning them, access is broken. If a private endpoint returns them intermittently, credentials may be expiring or rate limits may be kicking in. These should alert differently than hard failures.
404s are tricky. For content that should exist, a 404 is a real error. For dynamic paths or user-driven URLs, it may be normal. Monitoring should target known, stable URLs so a 404 always means something changed or was removed.
Rate limiting codes like 429 signal stress before failure. They tell you the system is alive but overloaded or misused. Repeated 429s often precede 500s. Alerting early here helps you act before users feel full downtime.
Do not alert on a single response. Transient network issues happen. Require consecutive failures or a short error window before triggering incidents. This reduces false positives without delaying real alerts.
Finally, pair status codes with timing. A 200 that takes ten seconds can be worse than a fast 500. Response time thresholds catch degradations that codes alone miss.
The goal is not to collect codes. It is to answer one question quickly: is the service reachable, behaving correctly, and responding fast enough for users right now?
Keeping tabs on HTTP status codes with Google search console and UptimeRobot
Google Search Console is an important tool to help you monitor and decode the various HTTP status codes your site is generating. By using the ‘Crawl Errors’ report, you can see if Google has encountered any problems when indexing your website.
While Google Search Console is comprehensive, it doesn’t explicitly identify all HTTP status codes, and you also won’t get alerts immediately when something goes wrong.
That’s where UptimeRobot steps in.
UptimeRobot will monitor your website so if your site goes down or starts generating 4xx or 5xx HTTP status codes, you’ll receive an alert.
This rapid notification allows you to quickly address issues and stay ahead of potential website hiccups that could impact your site’s SEO.
Once you detect HTTP code issues, make sure you look into it.
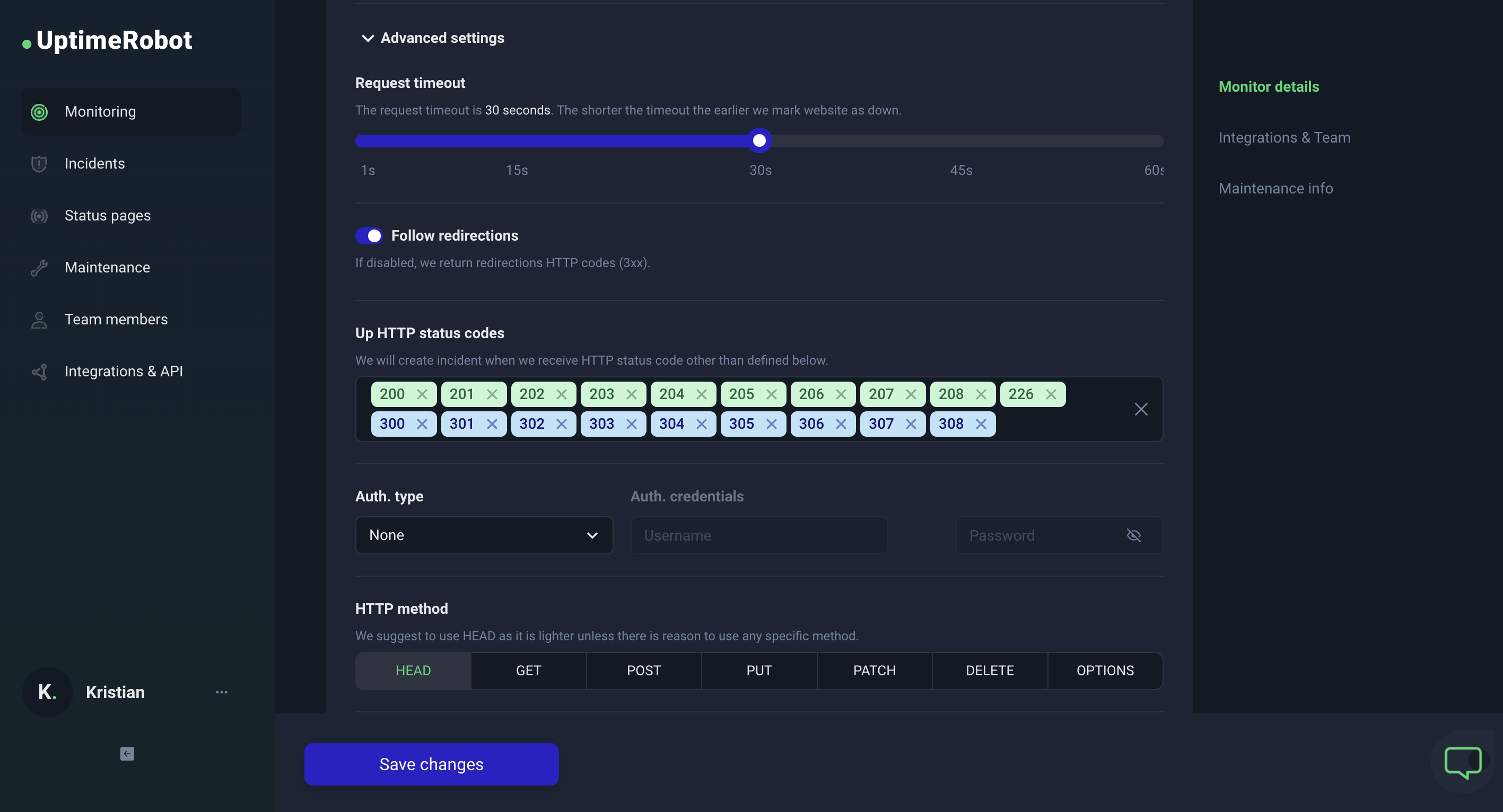
With UptimeRobot, you can choose which HTTP codes will be considered as UP or DOWN notifications.
Google’s John Mueller has a lot of interesting advice on how to remove errors (see the video below, where he discusses removing 404 errors from Google indexing). While this can be a long and tedious process, especially if you have a large website with many subpages, it’s crucial that you address the issues to ensure your SEO isn’t damaged.
Wrapping up
Understanding HTTP status codes can give you a wealth of information about the health and performance of your website.
By paying attention to these codes and managing them effectively, you can provide a smooth and enjoyable user experience for your customers and maintain your website’s SEO value.
Take advantage of tools like Google Search Console and UptimeRobot to help you monitor these status codes and address any issues promptly.
Remember, an informed website owner is an empowered website owner – so don’t let HTTP status codes remain a mystery!
FAQ's
-
HTTP status codes are standardized responses sent by a server to indicate the result of a request. They tell you whether a request succeeded, failed, or needs additional action. Each code helps pinpoint what happened between the client and server.
-
2xx codes mean the request succeeded, while 3xx codes indicate redirects. 4xx codes signal client-side issues like bad requests or missing auth, and 5xx codes point to server-side failures. Knowing the category helps narrow down responsibility quickly.
-
5xx status codes are the most common indicators of downtime because they mean the server failed to handle the request. Codes like 500, 502, and 503 often show backend or infrastructure problems. Persistent 4xx errors can also break user flows, even if the server is technically up.
-
A 200 status only confirms the server returned a response, not that the content is correct. Error pages, empty responses, or partially loaded apps can still return 200. Content checks or keyword validation help catch these cases.
-
Redirects (3xx codes) aren’t errors by default, but they can hide problems if misconfigured. Long redirect chains or loops increase latency and may cause failures. Monitoring should follow redirects and validate the final response.