Ping monitoring is often treated as a basic uptime check, yet it’s usually the first signal something is off. Latency creeps up, packets drop, or responses stop entirely, even though the service still appears “up.” Misreading these signals leads to slow or incorrect fixes.
This guide explains how ping monitoring works in real environments. It covers what ping can and can’t tell you, how networks handle ICMP traffic, and why results differ across regions, firewalls, and providers. The focus is on interpreting data, not just collecting it.
You’ll learn when ping is the right tool, how to spot early network issues, and how to use ICMP checks alongside other monitors for clearer alerts. If ping is part of your monitoring stack, this will help you trust it again.
By continuously monitoring network devices and services, ping monitoring ensures that any anomalies or disruptions are quickly detected and addressed.

How does ping monitoring work
Ping monitoring offers both significant benefits and some limitations. Understanding these can help optimize its use and integrate it with other tools for comprehensive network management.
Benefits of Ping Monitoring
- High frequency and automation: Ping monitoring operates on an automated basis, capable of running checks regularly (you set it up to run anywhere from every 30 seconds to every 24 hours) every 30 seconds, minute, hourly, or continuously 24/7 throughout the year. Once set up, it requires minimal maintenance — just sit back and wait for alerts to come through.
- Ease of setup and use: Setting up ping monitoring with UptimeRobot is straightforward and quick, often taking just 30 seconds to configure. Just a few clicks and you’ll be able to monitor things for FREE for life with just your email address and no strings attached (no credit card needed)
- Global testing capabilities: This monitoring tool can test connectivity from multiple global endpoints. This feature is crucial for identifying regional-specific issues versus those affecting all users, which is essential for services catering to an international user base.
- Layer-specific monitoring: Ping monitoring enables the creation of dedicated monitors for specific components of your infrastructure, such as databases, email clients, or websites. This allows for targeted monitoring of each element instead of a generalized approach for the entire system.
Drawbacks of Ping Monitoring
- Limited reporting on downtime causes: While ping monitoring is effective in detecting downtime, it doesn’t provide insights into the underlying causes. It focuses on the end result (whether a system is up or down) without going into the operational intricacies of the application.
- Restricted functional monitoring: Ping monitoring’s scope is confined to checking the status of specific IPs, potentially missing out on smaller yet critical issues that do not directly lead to downtime but can significantly impact user experience. For example, a website might be up, but certain functionalities may not work as intended.Other tools like Port monitoring, Domain monitoring, SSL expiry and errors monitoring, or Keyword monitoring within uptime checks are necessary to monitor such specific aspects and functionalities.
Understanding Ping Monitoring & ICMP
Ping monitoring offers a simple yet effective way to check the availability and responsiveness of internet destinations, be it an IP address or a domain.
At its core, it employs the Internet Control Message Protocol (ICMP) to perform its functions.
This automated process operates by regularly sending ICMP echo requests to a specified target and then analyzing the responses (or lack thereof) received. The frequency of these requests is predetermined, ensuring continuous monitoring.
When a service interruption or unresponsiveness occurs (what’s often referred to as downtime) ping monitoring identifies this anomaly.
It then triggers alerts to notify relevant development or IT team members. These alerts, part of a process known as incident alerting or on-call alerting, are integral in ensuring timely responses to potential issues.
UptimeRobot offers shared account access with different permissions (admin, write, read, and notify-only), so you decide who should be alerted when an issue comes up.
ICMP is a network layer protocol used for diagnosing network communication issues and facilitating messaging between network devices.
It essentially acts as a support mechanism for the internet, enabling the transmission of error messages and operational information, indicating whether a data transmission is successful or if the host is reachable.
The ping command, a widely available tool across various operating systems, uses ICMP to assess the reachability of a networked device or an IP address. It measures the round-trip time for messages sent from the originating host to a destination computer and back.
This measurement, in milliseconds, is a critical indicator of network performance and the health of the connection. A successful ping will receive a response from the target, confirming its accessibility and the time taken for the round trip.
ICMP operates through two primary message types: echo requests and echo replies. An echo request is sent by a host to a network destination, requesting a response.
Upon receiving this request, the destination device sends back an echo reply, confirming its presence and connectivity.
This exchange of messages is fundamental in identifying network status and device accessibility, playing a vital role in maintaining smooth internet communication.
By understanding and employing ping monitoring and ICMP, network administrators can keep tabs on timely identification and resolution of network issues.
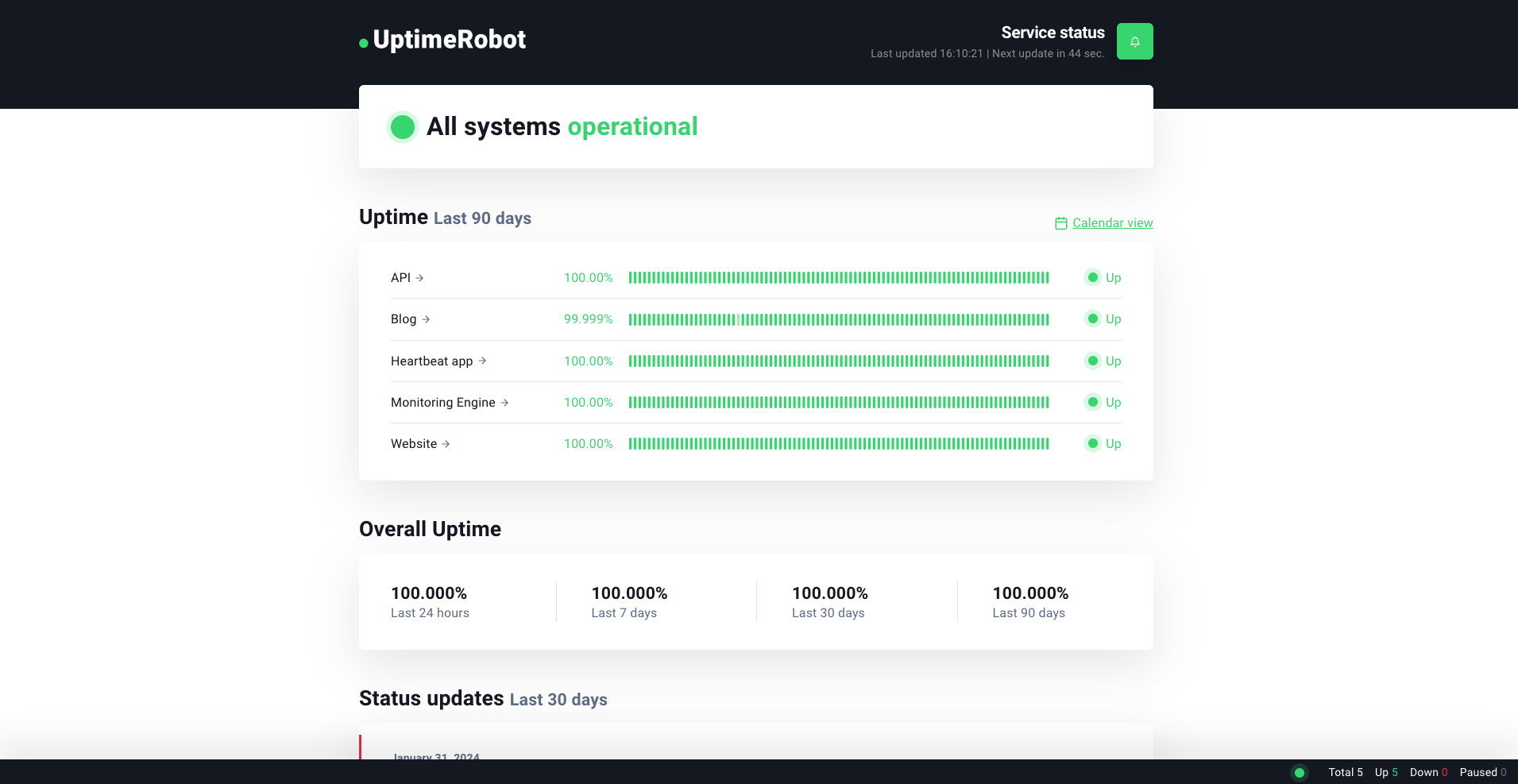
Downtime incidents & alerts
A downtime incident occurs when a network service, such as a website, server, or IP address, becomes unavailable or unresponsive.
Best practices to recover from a downtime incident
- Quick detection: The first step in recovering from a downtime incident is prompt detection. This is where ping monitoring plays a crucial role, as it can alert network administrators immediately when a service becomes unresponsive. This is why shorter monitoring intervals like 30 seconds can be more effective compared to 5 minutes — you can take action within seconds of an issue occurring.
- Diagnosis: Once notified, check server logs, examine recent changes in the network configuration, or assess any external factors that might have affected the service.
- Resolution: Restart servers, reroute network traffic, or address specific hardware or software issues as needed.
- Communication: Let stakeholders, including users and team members, know about the downtime and the expected resolution time. You can use UptimeRobot’s Status pages to do this.
How to prevent downtime incidents
- Regular monitoring and maintenance: Continuous monitoring of network performance using tools like ping monitoring can help identify potential issues. Regular maintenance and updates of network infrastructure also play a key role in preventing incidents.
- Redundancy and failover systems: Implementing redundancy in critical network components and having failover systems in place can significantly reduce the likelihood of downtime. This ensures that if one component fails, others can take over its function without affecting service availability.
- Capacity planning and stress testing: Regularly assessing the network’s capacity and conducting stress tests can help in understanding how the network behaves under different load conditions. This helps in planning for necessary upgrades and scalability to handle peak loads without service disruptions.
- Employee training and awareness: Ensuring that team members are well-trained and aware of the best practices in network management can prevent human error, which is a common cause of downtime.
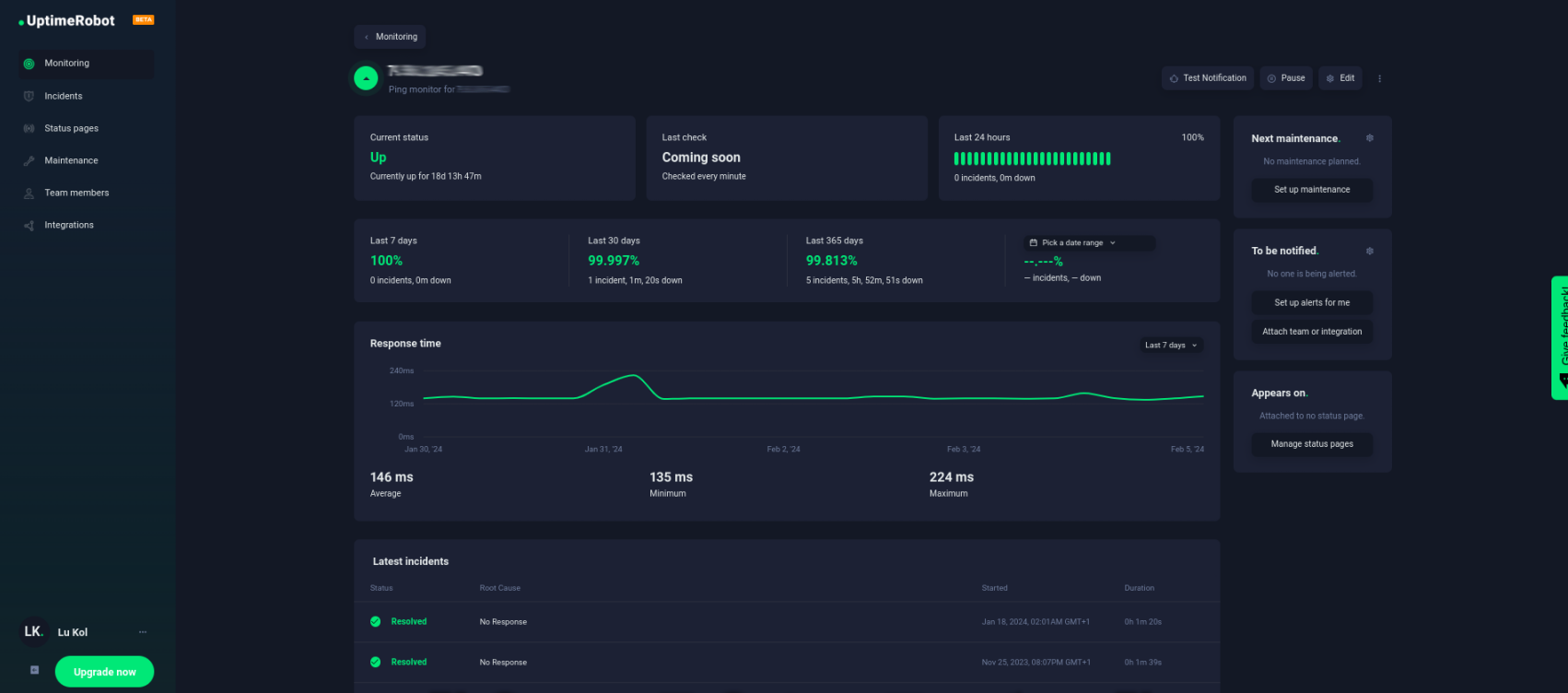
Ping monitoring checks & alerts
These alerts provide detailed information about network incidents, pinpointing exactly which monitor experienced a problem and when.
There are three primary scenarios in which a ping monitoring alert might be triggered:
- No response from the host: This occurs when the host being monitored does not respond to ping requests at all.
- Complete packet loss: This situation arises when the ping requests are sent, but no packets are returned from the host.
- Partial packet loss: In this case, some, but not all, of the packets sent to the host are returned.
Different Types of Ping Monitoring Checks
Ping monitoring can be customized based on packet size, which allows for a more nuanced understanding of network performance under different conditions. Here are examples of different checks:
- 64 Bytes check: This check involves sending packets of 64 bytes, with 56 bytes of payload and an 8-byte header. If there’s no packet loss in this check, the network is generally considered to be functioning well. However, any packet loss here could indicate significant network issues.
Example: ping -c 4 -s 56 192.168.0.1 - 512 Bytes check: This check ups the packet size to 512 bytes (504 bytes payload, 8 bytes header). Packet loss tends to start showing with larger packets, and even a 1 or 2-packet loss could be significant.
Example: ping -c 4 -s 504 192.168.0.1 - 1024 Bytes check: The largest of the standard checks, using packets of 1024 bytes (1016 bytes payload, 8 bytes header). This check is crucial for identifying issues with large packet transmissions, where packet loss may be 50% or more.
Example: ping -c 4 -s 1016 192.168.0.1
When ICMP ping monitoring is the right tool (and when it isn’t)
ICMP ping monitoring answers one narrow question: can this host be reached on the network right now? That simplicity is both its strength and its limit.
Ping works best for detecting hard failures. If a server drops off the network, loses routing, or becomes unreachable due to infrastructure issues, ICMP catches it fast. This makes it useful for baseline availability checks on servers, routers, and network devices.
It is also lightweight. Ping does not depend on application stacks, ports, or services being up. Even a mostly broken system can still reply to ICMP, which helps separate network-level failures from higher-layer problems.
However, reachability is not service health. A host can respond to ping while the web server is down, the database is unreachable, or the application is returning errors. ICMP success only proves the network path exists, not that users can do anything useful.
Firewalls complicate interpretation. Many environments block ICMP by design. In those cases, failed pings do not indicate downtime. They indicate policy. Monitoring teams need to know whether ICMP is allowed before trusting results.
Latency trends are where ping adds more value over time. Gradual increases in round-trip time often signal congestion, routing changes, or resource pressure upstream. These slowdowns tend to appear before full outages and can act as early warnings.
Single-location checks are another limitation. Network issues are often regional. A host may respond from one location while timing out from another. Multi-location ping checks reduce blind spots and better reflect real user reachability.
Because of these constraints, ICMP ping should rarely stand alone. It works best as a foundation signal, paired with checks that validate real services. HTTP monitoring confirms applications respond correctly. Heartbeat checks confirm background jobs run.
Think of ping as a smoke detector for the network layer. It tells you something is wrong quickly, but it cannot explain what broke inside the building.
The importance of ping monitoring
Ping monitoring stands as an essential tool in network management, crucial for ensuring optimal network performance and uptime.
As a fully automated process, its proactive nature enables it to operate with high frequency, potentially checking the network status as often as every few seconds.
This rapid cycle allows for the immediate detection of issues, facilitating quick response and resolution. Ideally, such swift actions can resolve downtime incidents before they significantly impact users, minimizing the number of affected individuals.
Core functions of ping monitoring:
- Assessing availability: It serves as a fundamental method for assessing the availability of IP addresses. This basic yet effective approach is often the starting point in troubleshooting network downtime issues.
- Simplicity and clarity: Its simplicity offers an advantage over more complex monitoring methods, such as HTTP or API monitoring, by providing a clear, initial overview of the network’s status.
Over time, the consistent application of ping monitoring yields a wealth of data regarding application performance, including critical metrics like uptime and response times.
Such a dataset is invaluable for benchmarking purposes, allowing network administrators to compare their network’s performance against that of competitors or previous iterations of their own network setups.
How to set up ping monitoring
Setting up ping monitoring is a straightforward process with UptimeRobot, which provides reliable and user-friendly interfaces for infrastructure monitoring. Here’s a step-by-step guide to get you started on monitoring the availability of an IP address using UptimeRobot:
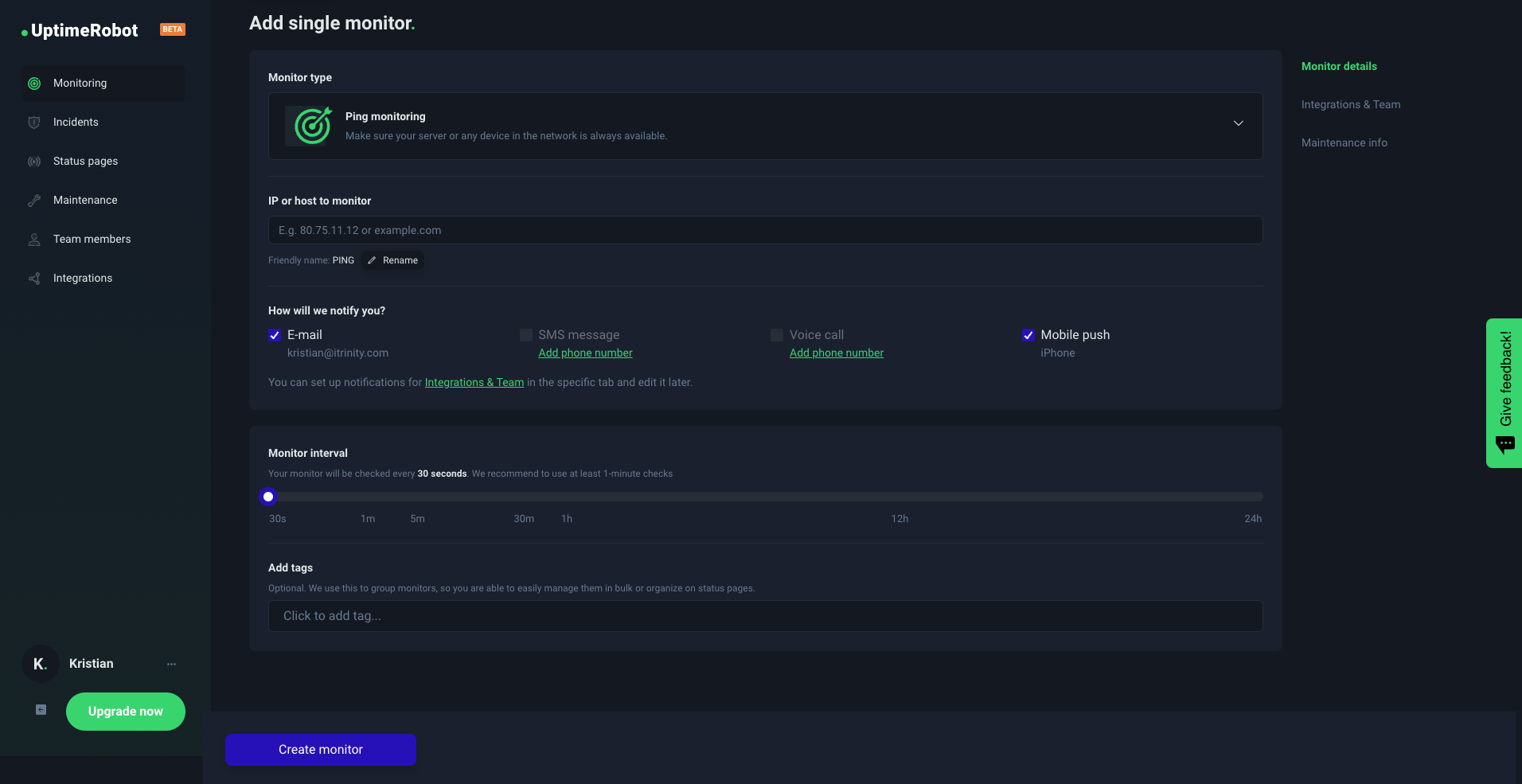
- Sign up and log in: First, create a free account with just your email address and log in. This is your entry point to accessing various monitoring services.
- Click on the blue “New monitor” button.
- Choose Ping monitoring and add all details, such as the IP or URL address and friendly name.
- Choose how we’ll notify you: Pick one of the native notification options like E-mail, SMS message, Voice call, or Mobile push.
- Choose your monitoring intervals: From 5 minutes for a free account or 1 minute (or 30 seconds) for a paid.
- Add tags if you want to group your monitors.
- Click on the “Create monitor” button and that’s it!
This setup will alert you whenever the specified IP address fails to respond to ping requests, helping you stay on top of your network’s availability and performance.
Conclusion
Ping monitoring plays a crucial role in ensuring network availability.
By leveraging ICMP and the ping command, you get a simple yet effective way to diagnose and maintain network stability. This method is key for detecting downtime incidents, understanding network behavior through various ping checks, and troubleshooting effectively.
Despite its limitations in in-depth diagnostics, ping monitoring remains an indispensable component for robust network management in our increasingly connected digital landscape.
FAQ's
-
ICMP ping monitoring checks whether a host is reachable over the network using ICMP echo requests. It confirms basic network connectivity and response time. This makes it useful for monitoring servers, routers, and network devices.
-
It tells you if a device responds to network-level requests and how long that response takes. It does not verify whether applications or services are working. A host can respond to ping while the service on it is broken.
-
Many firewalls, cloud providers, and security policies block or rate-limit ICMP traffic. In those cases, the server may be healthy but intentionally not responding to ping. This is common in production environments.
-
It’s reliable for detecting network outages and host-level reachability issues. However, it can’t detect application failures or partial outages. ICMP works best as a low-level signal, not a full health check.
-
False alerts usually come from temporary packet loss, network congestion, or ICMP rate limiting. Strict timeouts or missing retries can amplify this noise. Adding retries and grace periods helps reduce false positives.