Incidents don’t start as incidents. They begin as small signals: a slow endpoint, a failed job, a vague alert no one owns. When there’s no clear process, those signals get missed, and recovery time stretches fast.
This guide explains incident management in practical terms. It focuses on how teams detect issues, decide what matters, coordinate response, and communicate while systems are under pressure. The emphasis is on real workflows, not theory or certification language.
You’ll learn what incident management actually involves, why teams struggle with it, and how a clear process reduces downtime and confusion. If outages still feel chaotic, this is where to build structure.

In this article, we’ll cover the following key topics:
- Incident management minimizes downtime and ensures operational stability by providing a structured approach to resolving issues.
- It enhances response times and system reliability, helping organizations maintain seamless performance.
- Different types of incident management offer tailored solutions for various operational needs.
- A clear IT incident management process enables quick identification and resolution of technical issues.
- DevOps incident management integrates speed and efficiency into handling incidents.
- Incident management tools streamline monitoring, tracking, and resolution of problems.
- UptimeRobot’s proactive incident management ensures high system availability and reliability.
What is incident management?
Incident Management is a structured process to restore services to normal as quickly as possible following a disruption. Beyond just reacting to issues, this approach also helps businesses to proactively identify potential issues and implement preventive measures, reducing the likelihood of future disruptions.
By following effective incident management practices, businesses can not only reduce downtime and mitigate risks but also enhance service reliability and ensure a seamless, uninterrupted experience for their users.
Benefits of incident management
Here are some key benefits of implementing an effective incident management system:
- Minimized business impact: Effective incident management helps to minimize business impacts by ensuring swift detection and response to issues, preventing them from escalating into full-blown crises.
- Accelerated incident resolution: Speed is critical when dealing with incidents. While the average company takes 197 days to identify and 69 days to contain a breach, effective incident management shortens these timelines. This reduces financial impact and boosts overall resilience.
- Enhanced customer satisfaction: Customers appreciate quick resolution during a crisis. Rapidly addressing incidents helps maintain high service quality and ensures that customer expectations are met even during disruptions.
- Proactive monitoring and improvement: Incident management involves continuous monitoring of systems and processes. By anticipating and preventing future issues, organizations can reduce the likelihood of significant disruptions.
- Cost efficiency: Organizations that resolve breaches within 30 days can save over $1 million. Effective incident management reduces both the direct costs of breaches and related expenses like downtime and customer impact.
Let us look at a recent real-world example that highlights the importance of effective incident management. On Friday, July 19, a faulty update from CrowdStrike rendered 8.5 million Windows PCs and servers inoperable. The impact was widespread, affecting banks, airlines, TV broadcasters, supermarkets, and even Starbucks, whose systems crashed due to the issue.
By Monday, Delta Airlines had canceled over 600 flights as it struggled to resolve the issue. This incident, as reported by Vault, demonstrates the urgent need for swift incident management to minimize impact across industries.
The types of incident management
Incident management processes can vary depending on organizational needs and the nature of the incident. Organizations may adopt different approaches, including:
- IT service management process
ITSM process primarily focuses on efficiently managing and delivering IT services. The approach utilizes structured processes, often based on frameworks like ITIL, to systematically handle incidents. The goal is to quickly restore normal service operations and minimize business disruptions. ITSM is generally more reactive, focusing on addressing incidents after they occur.
- Site reliability engineer process
The SRE process combines software engineering with operations to enhance system reliability. While it manages incidents as they arise, the SRE process places a strong emphasis on prevention. This is achieved through proactive monitoring, automation, and scalability to avoid incidents. The SRE process involves designing robust, resilient systems and continuously measuring and improving reliability.
- DevOps-inspired incident process
DevOps process merges development and operations to improve software delivery and system reliability. This approach centers on continuous delivery and infrastructure as code, viewing Incidents as opportunities for improvement. The response usually involves fixing the immediate problem and then improving development and deployment processes to prevent similar issues in the future.
- Reactive incident management
This approach focuses on addressing incidents as they happen. It involves dealing with issues after they have occurred. The main aim is to minimize the impact and restore normal operations as quickly as possible.
- Proactive incident management
This approach involves taking preemptive measures to avoid incidents. It includes activities like risk assessment, continuous monitoring, and preventive maintenance to anticipate and mitigate potential issues before they arise.
Understanding incident categories and severity
Here’s the third cardinal truth of incident management: not all incidents are the same.
Dealing with an outage that affects just 20% of your users is a whole different ball game compared to one that impacts 90% or even 100%. That’s why it’s so important to have clear severity levels in place and a solid plan for prioritizing incidents as they come up. This helps ensure that the most critical issues get the attention they need, fast.
Here’s how you can categorize your incidents to make sure you’re addressing them effectively.
- Low severity (minor incident)
These incidents cause little to no disruption to business operations. They are often routine issues or minor technical glitches.
Actions:
- Log the incident and acknowledge the report
- Minimal impact; can be handled by the local team or IT helpdesk.
- No urgent action needed; resolution is scheduled.
Example: A user having trouble logging in due to an outdated password.
- Medium severity (moderate incident)
These incidents cause a moderate level of disruption but do not pose an immediate threat to critical business functions. It may affect a department or team, but does not halt overall operations.
Actions:
- Assess the scope and impact on business functions.
- Immediate corrective action is taken to resolve the incident.
- Incidents should be resolved within a defined service level agreement (SLA).
Example: A software bug affecting multiple users, but with a workaround in place.
- High severity (major incident)
These incidents cause significant disruption, affecting business-critical functions and/or a large portion of the user base. Immediate action is required to mitigate the impact.
Actions:
- Notify the appropriate stakeholders immediately.
- Escalate the incident to higher-level support teams or management.
- Aim for resolution within a short time frame, possibly involving a dedicated team.
Example: A server failure affecting an entire department or a system outage preventing users from accessing vital services.
- Critical severity (severe incident)
These incidents pose an immediate, significant threat to the business or public safety. They typically involve security breaches, data loss, or system outages that affect critical business operations.
Actions:
- Declare an emergency and engage all relevant teams.
- Apply emergency mitigation strategies (such as taking the system offline).
- Regularly update stakeholders and executives.
- Root cause analysis to prevent recurrence and ensure recovery.
Example: A cyberattack or data breach that threatens sensitive customer information.

Incident management frameworks & compliance standards
When managing incidents, organizations have access to various frameworks that guide their response efforts. Let’s take a closer look at some key frameworks and compliance standards that are crucial for effective incident management.
NIST cybersecurity framework (NIST CSF)
The National Institute of Standards and Technology (NIST) developed a comprehensive incident response framework outlined in their Computer Security Incident Handling Guide. The NIST incident response lifecycle consists of six main phases:

Source: NIST
- Govern
- Identify
- Protect
- Detect
- Respond
- Recover
This framework emphasizes prevention, thorough analysis, strategic containment, and continuous improvement through lessons learned.
SANS incident management framework
The SANS Institute framework takes a practical, hands-on approach grounded in real-world experience. It encourages organizations to focus on both immediate incident response and long-term improvements. Key aspects include:

- Preparation
- Identification
- Containment
- Eradication
- Recovery
- Lessons learned
ISO 27001
ISO 27001 provides a structured approach to incident management that aligns with broader information security management practices. Key phases in the ISO 27001 incident response process include:

- Identification
- Analysis
- Containment
- Eradication
- Recovery
- Post-incident review
ISO 27001 emphasizes the importance of clear procedures, consistent responses, and compliance with regulatory requirements.
ITIL (Information Technology Infrastructure Library)
ITIL frames incident management as a vital component of IT service management (ITSM). Key aspects of ITIL incident management include:

- Incident identification
- Incident logging
- Categorization and prioritization
- Initial diagnosis
- Escalation
- Resolution and recovery
- Incident closure
- Review and reporting
ITIL emphasizes the integration of incident management with other IT processes like problem management and change management.
How different industries handle incident management
Different industries handle incidents based on their unique operational requirements, regulatory environments, and customer expectations. Here’s a comparison of how banking, e-commerce, and SaaS industries manage incidents:
Banking
Banks operate in a highly regulated and risk-sensitive environment, where even minor incidents can have major legal, financial, and reputational consequences. Given the sensitive nature of financial data and customer trust, effective incident management is mandatory.
How banks handle incident management:
- Regulatory compliance: Banks follow strict guidelines like GDPR, PCI-DSS, SOX, and FDIC regulations to ensure comprehensive incident response plans.
- Incident grading: They use grading systems to assess severity and determine escalation levels.
- Cross-functional teams: Incident response involves experts from legal, IT security, HR, and operations.
- Proactive risk management: Activities like penetration testing and tabletop exercises help identify vulnerabilities.
- Customer notification: Timely communication with affected individuals is required by law in case of data breaches.
- Evidence preservation: Banks focus on gathering evidence for potential legal or regulatory proceedings.
SaaS
SaaS companies need to ensure that their services are always available, even as they scale globally. They rely heavily on cloud infrastructure to support continuous availability and rapid issue resolution. This dependency on the cloud makes incident management especially important, as service disruptions can affect customers across multiple regions.
How SaaS companies handle incident management:
- Full-service ownership: Development and operations teams manage services from design to resolution.
- Automation: Automated monitoring tools detect issues early to prevent disruptions.
- Collaboration across teams: Developers, IT operations, and customer support work together for swift resolution.
- Continuous improvement: Post-mortem analyses refine processes and prevent recurrence.
- Global scalability: SaaS providers ensure seamless incident handling across regions.
E-commerce
E-commerce companies rely on uninterrupted service to drive sales and customer satisfaction. Any downtime, even for a short period, can lead to lost revenue and damage to brand reputation. With high traffic volumes, especially during peak seasons, these companies prioritize incident management to quickly resolve issues.
How e-commerce businesses approach incident management:
- 24/7 monitoring: Around-the-clock monitoring to detect issues quickly.
- Customer impact minimization: Prioritize customer-facing services to reduce downtime.
- Rapid response: Dedicated incident response teams available at all times.
- Scalability: Systems designed to handle traffic spikes during peak shopping periods.
Continuous improvement: Post-mortem analysis to avoid recurrence of incidents.
IT incident management process: Step by step
To implement an effective IT incident management system, follow these six key steps:
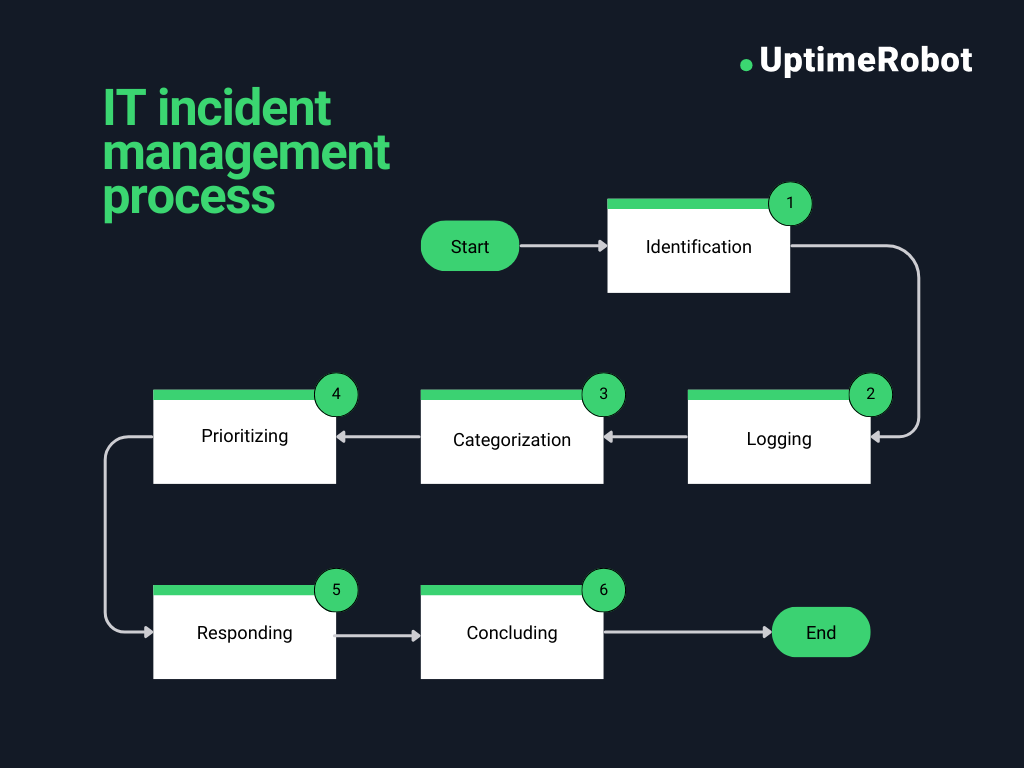
1. Identification
The first step involves identifying incidents, which can be reported by employees, end-users, or monitoring systems through various channels such as phone, email, SMS, web forms, or live chat. After receiving a report, the service desk team records the incident and determines whether it is an incident or a service request, as they are handled differently.
2. Logging
Once identified, the incident must be logged in the service desk or help desk software. The ticket should include detailed information such as:
- Name and contact of the person who reported the incident.
- Date and time of the incident report.
- Incident description along with what is not working properly or went down.
- A unique incident ID for tracking the incident.
3. Categorization
Incidents should be assigned appropriate categories and subcategories to help in sorting and prioritizing. For instance, an incident categorized as “Network Outage” will be treated with higher urgency due to its significant impact. Proper categorization helps in organizing incidents and identifying recurring patterns.
4. Prioritizing
After categorization, incidents must be prioritized based on their impact and urgency using a priority matrix. The impact measures the potential damage to the business, while the priority determines the resolution time frame. Incidents are classified as critical, high, medium, or low.
5. Responding
The response phase involves a series of steps in a specific order to resolve the incident:
- Initial diagnosis: Assess the issue and gather the necessary information.
- Incident escalation: If needed, escalate to higher-level support.
- Investigation and diagnosis: Conduct a thorough investigation to pinpoint the root cause.
- Resolution and recovery: Implement solutions to resolve the incident and recover services.
6. Concluding
After the resolution, follow up with the reporter to confirm that the issue has been fully resolved. This step, known as incident closure, ensures satisfaction with the resolution and completes the incident management process.
“Successful incident management is not just about quick fixes but more about understanding the root cause and preventing recurrence. A systematic approach allows teams to tackle incidents methodically, reducing downtime and enhancing overall resilience.” — Alex, Head of DevOps at UptimeRobot
DevOps incident management process – step by step
Here are the five steps that will help you implement efficient DevOps incident management.
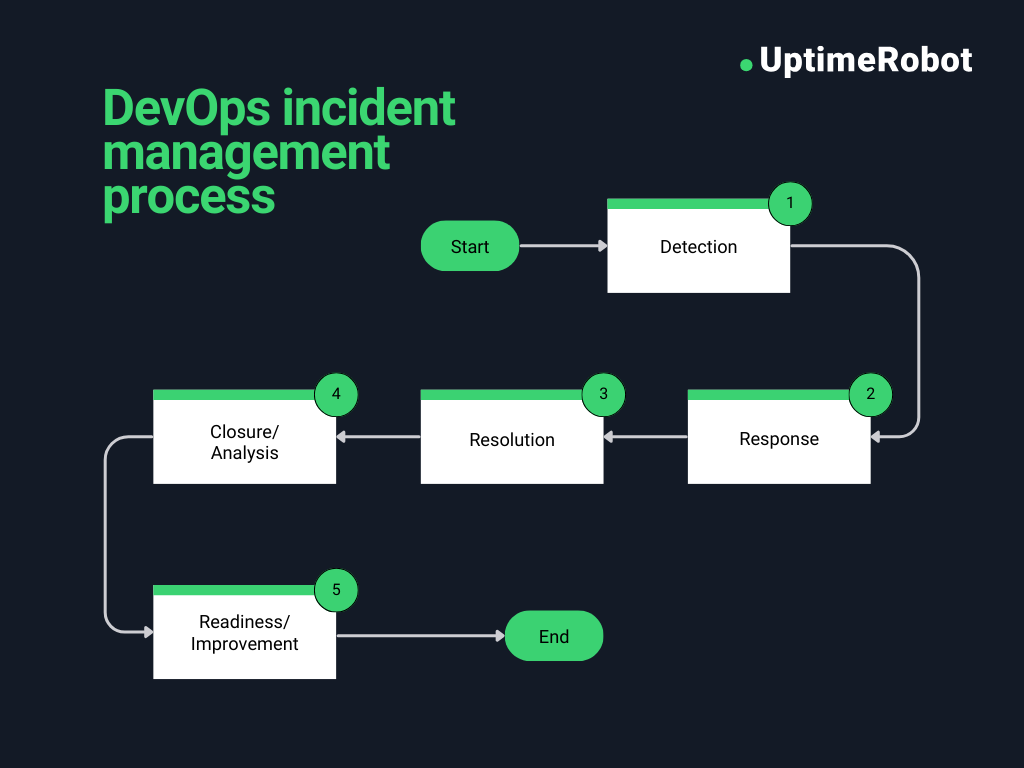
1. Detection
Incidents are inevitable, so DevOps teams prioritize preparedness. They implement monitoring tools, alert systems, and runbooks to ensure timely detection of issues. Once an incident is identified, it must be recorded in a ticketing system to initiate the response process.
Uptime monitoring continuously tracks system health, latency, and uptime, triggering alerts when anomalies are detected. These alerts, based on predefined thresholds, allow teams to act before users are impacted. Integrating monitoring with incident management ensures that alerts are logged, categorized, and escalated to the right responders without unnecessary delays.
Once an alert is received, teams use either manual or automated escalation strategies.
In manual escalation, an on-call engineer reviews the alert, assesses its severity, and decides whether to escalate it to senior staff or another department. While this allows for human judgment, it can introduce delays, especially if the issue occurs outside working hours.Automated escalation eliminates delays by following predefined rules to escalate incidents based on severity and response time. If an alert remains unacknowledged, the system automatically escalates it to the next responder, ensuring faster resolution and minimized downtime.
2. Response
The on-call engineer reviews information from monitoring tools and leads the response. If the issue is complex, a runbook provides guidance, and additional experts may be brought in to assess and escalate the incident as needed.
3. Resolution
DevOps teams, being familiar with the application or system code, typically resolve incidents quickly. Their deep understanding and advanced preparation allow them to address issues efficiently, often faster than external teams unfamiliar with the code.
4. Closure/Analysis
Once an incident is resolved, the next step is conducting a postmortem analysis to review what happened, extract key learnings, and implement improvements. This structured review helps teams identify the root cause, evaluate the effectiveness of the response, and establish preventive measures to reduce the likelihood of recurrence.
A postmortem report provides a detailed breakdown of the incident, ensuring a structured approach to learning and improvement. It typically includes:
- Incident summary: A high-level overview of what happened.
- Impact assessment: The effect on customers, systems, and business operations.
- Root Cause Analysis (RCA): Investigation into the underlying cause.
- Incident response evaluation: Reviewing what worked well and what didn’t.
- Preventive actions & next steps: Implementation of fixes and process improvements.
For reference, explore different incident postmortem templates:
5. Readiness/Improvement
Following resolution and analysis, the team updates runbooks and adjusts monitoring tools based on lessons learned. This ongoing refinement ensures better preparedness for future incidents.
To keep the team sharp and effective, Alex, Head of DevOps at UptimeRobot, advises, “Conduct regular incident response drills to keep your team sharp. Simulating incidents helps ensure that everyone knows their role and can execute the response plan efficiently when a real incident occurs.”
How teams analyse incidents
Teams conduct Root Cause Analysis (RCA) to identify the underlying issue behind an incident. The RCA process includes:
- Data collection: Gathering logs, alerts, system reports, and witness accounts.
- Event timeline: Mapping out the sequence of events leading up to the incident.
- Impact analysis: Assessing affected users, services, and business operations.
- Root cause identification: Using problem-solving techniques to determine the cause.
Common RCA methods include:
- 5 Whys Technique: Asking “Why?” repeatedly to trace the issue to its root cause.
- Fishbone Diagram (Ishikawa Diagram): Categorizing potential causes (e.g., process, technology, human error).
- Fault Tree Analysis: Using a structured diagram to map out failures leading to the incident.
Once the root cause is identified, teams implement measures to prevent future incidents. Key strategies include:
- Strengthening monitoring & alerting
- Deploying advanced monitoring tools to detect anomalies.
- Configuring alerts to trigger before issues escalate.
- Using AI-driven tools for proactive incident detection.
- Improving infrastructure & security
- Regular updates to eliminate vulnerabilities.
- Ensuring data is protected and recoverable.
- Implementing redundancy and failover mechanisms.
- Process optimization & documentation
- Refining response workflows for faster action.
- Learning from incidents and applying process improvements.
- Ensuring security and compliance standards are up to date.
- Training & simulations
- Running simulated attacks and failures to test preparedness.
- Educating teams on new threats, tools, and protocols.
- Creating a centralized knowledge base of past incidents and resolutions.
Incident management tools
Effective incident management relies on a range of tools designed to streamline the process from detection to resolution. Here are some of the most common incident management tools:
1. Monitoring tools
With 54% of organizations encountering downtime incidents lasting at least eight hours, monitoring tools are essential. They help identify outages, trigger alerts, and diagnose incidents. By automating issue detection, these tools reduce operational costs and allow DevOps teams to concentrate on software development.
Example: UptimeRobot
UptimeRobot is a leading uptime monitoring service designed to keep your websites and services online. It offers a free plan that includes 50 monitors with 5-minute checks. For more advanced features, like frequent checks every 60 seconds and enhanced alerting, the Pro plan starts at $7 per month. UptimeRobot has a G2 score of 4.6/5.
User Review:
“In a matter of seconds, you create a sensor and you are already monitoring your service. In addition, the free version has everything you need, if you are a professional you may need the paid version” – G2 Review
2. Root cause analysis tools
These tools analyze operational data, including logs from system management, application performance monitoring, and infrastructure monitoring. They help pinpoint the exact location and cause of incidents by understanding system operations and identifying underlying issues.
Example: Splunk
Splunk is a powerful tool for root cause analysis, offering comprehensive data analysis capabilities across IT operations. Splunk’s pricing starts with a free plan that allows limited data ingestion, with enterprise plans that can be customized based on your needs. Splunk has a Capterra rating of 4.6/5.
User Review:
“Splunk has been key in identifying the root causes of major issues by analyzing logs and from that being able to build reports and determine causes of issues” – Capterra Review
3. AIOps platform
AIOps platforms leverage historical data and logs to enhance decision-making, optimize resource allocation, and accelerate incident response. Organizations using AIOps for incident management have reported up to a 50% reduction in IT costs due to improved efficiency and faster issue resolution.
Example: Moogsoft
Moogsoft offers an AIOps platform that leverages machine learning to analyze IT operations data, providing context for better decision-making and faster incident response. It features a free trial, with pricing tailored to enterprise needs. Moogsoft has a G2 score of 4.5/5.
User Review:
“The way the alerts and situations populated is easy to play around.” – G2 Review
4. Incident tracking
These tools document incidents throughout their lifecycle, from detection to resolution. They facilitate assigning incidents to appropriate teams, tracking progress, and maintaining a historical record. This data is valuable for identifying patterns, improving procedures, and training new team members.
Example: ServiceNow
ServiceNow provides comprehensive incident tracking and management capabilities. Pricing starts at approximately $100 per user per month, with a free trial available. ServiceNow has a Capterra score of 4.5/5.
User Review:
“I have used ServiceNow on multiple projects, mainly for incident tracking. It has worked very well for our teams.” – Capterra Review
5. Service desk tools
Service desk tools enable users to submit tickets, communicate with support teams, and track progress. They typically feature request management systems that assist with prioritizing and categorizing incidents, improving the efficiency of incident management. Automating processes can resolve 22% of service desk tickets at virtually no cost, compared to $22 for manual handling.
Example: Zendesk
Zendesk offers a versatile service desk solution that supports ticket management, customer communication, and incident resolution. It has a free trial, with pricing starting at $19 per agent per month. Zendesk has a G2 score of 4.3/5.
User Review:
“We are able to answer and solve so many more problems by using Zendesk Support.” – G2 Review
6. AI and virtual agent tools
AI and virtual agents are transforming incident management by enhancing prediction, detection, and resolution using insights from past incidents. These virtual agents, like chatbots, offer instant responses and basic troubleshooting, handling up to 80% of common customer service inquiries. This allows human agents to focus on more complex tasks.
Example: IBM Watson
IBM Watson Assistant uses AI to provide virtual agent capabilities, offering instant responses and basic troubleshooting. It integrates with various systems to enhance incident management. Pricing starts at $120 per month, with a free plan available. IBM Watson Assistant has a G2 score of 4.2/5.
User Review:
“The services available on the platform are all incredible and I personally used and loved the chatbot service and text-to-speech service” – G2 Review
7. Documentation tools
Documentation tools automate the recording of environmental changes and incident details, aiding in postmortem analysis. For example, PowerCLI scripts can be scheduled to capture incidents for deeper analysis. These tools help document incident states and postmortems effectively.
Example: Confluence
Confluence by Atlassian helps document incident details, changes, and postmortem analyses in an organized and accessible manner. It starts at $10 per user per month, with a free plan for small teams. Confluence has a Capterra score of 4.5/5.
User Review:
“Excellent for creating, organizing, and sharing documentation within teams. Helps to serve as a single source of the information project” – G2 Review
| Platform/Tool | Top Features | Pros | Cons | Price | User review |
| Jira | Incident tracking, workflow automation, integrations, reporting | Highly customizable, integrates with DevOps tools | Steep learning curve, not as robust for non-IT incidents | Varies (starts at $7/user/month) | 4.2/5 (G2) |
| ServiceNow | Comprehensive ITSM, Methodical Incident Management | Enterprise-level features, strong security & compliance | Expensive for small teams, complex to implement | Starts around $100/user/month | 4.3/5 (G2) |
| PagerDuty | Event Intelligence, On-Call Management, 700+ Integrations | Real-time alerts, easy escalation, great integrations | Can be expensive for small teams, complex setup | Starts at $19/month | 4.5/5 (G2) |
| UptimeRobot | Uptime monitoring, alerting, status page, integrations | Affordable, easy to set up, supports many integrations | Limited to uptime monitoring, no incident resolution tools | Free plan, Pro starts at $7/month | 4.7/5 (G2) |
| Splunk | Automated Routing, Post-Incident Reviews, ML Capabilities | Powerful data analytics, scalable for large teams | Expensive, steep learning curve | Free for limited usage, enterprise pricing customized | 4.6/5 (Capterra) |
| OpsGenie | Advanced Routing, Incident Timeline, Mobile Apps | Easy to use, powerful alerting & integration capabilities | Can become costly for larger teams, interface can be cluttered | Starts at $9/user/month | 4.7/5 (Capterra) |
Incident recovery lessons from real-world outages
When major outages occur, organizations are forced to navigate through crisis management, recovery, and post-mortem analysis. By looking at some of the most high-profile service disruptions, we can gain valuable insights into how incident recovery works in practice.
2021 Facebook outage
On October 4, 2021, Facebook and its subsidiaries (Instagram, WhatsApp, Messenger, Oculus, and Mapillary) experienced a global outage lasting approximately 7 hours and 11 minutes
What went wrong?
The outage was caused by a misconfiguration in Facebook’s Border Gateway Protocol (BGP) routing. During routine maintenance, a command was accidentally run that disconnected all of Facebook’s data centers globally. This led to the withdrawal of BGP routes to Facebook’s Domain Name System (DNS) servers, making them unreachable from the internet.
Recovery process:
- Facebook’s engineering team had to physically access their data centers to reset the servers.
- BGP routes were gradually restored, allowing DNS services to become available again.
- Application-layer services were gradually restored over the following hour.
Lessons learned:
- The importance of having diverse and redundant systems to prevent single points of failure.
- The need for robust remote access systems that can function independently of the main infrastructure.
- The critical role of proper change management and safeguards in network configuration processes.
2017 Amazon Web Services (AWS) S3 Outage
On February 28, 2017, Amazon’s Simple Storage Service (S3) in the Northern Virginia region experienced a significant disruption that affected numerous websites and services.
What went wrong?
An authorized S3 team member, while debugging an issue with the S3 billing system, executed a command that was intended to remove a small number of servers. However, due to an incorrectly entered input, a larger set of servers was removed than intended. his affected two critical S3 subsystems: the index subsystem and the placement subsystem.
Recovery process:
- The affected subsystems required a full restart, which took longer than expected due to the massive growth of S3 and the fact that these systems hadn’t been fully restarted in years.
- The index subsystem was gradually restored, allowing S3 to begin servicing GET, LIST, and DELETE requests.
- The placement subsystem was recovered last, after which S3 returned to normal operation.
Lessons learned:
- Amazon modified their tools to remove capacity more slowly and added safeguards to prevent capacity from being removed below the minimum required levels.
- They began auditing other operational tools to ensure similar safety checks were in place.
- Amazon prioritized further partitioning of the index subsystem to improve recovery times.
- They changed the AWS Service Health Dashboard to run across multiple AWS regions to ensure status updates during future outages.
2020 Google Cloud Outage
On December 14, 2020, Google experienced a global outage affecting multiple services, including Google Cloud Platform, Google Workspace (formerly G Suite), Gmail, YouTube, Google Drive, and other authenticated services. The outage lasted approximately 50 minutes.
What went wrong?
The root cause was an issue in Google’s automated storage quota management system. This system inadvertently reduced the capacity of Google’s central identity management system, causing it to return errors globally. As a result, Google couldn’t verify user authentication requests, leading to errors for users trying to access various Google services.
Recovery process:
- Google engineers detected the issue within seconds but took longer than expected to diagnose and correct the problem.
- At 04:08 AM PST, the root cause and a potential fix were identified.
- At 04:22 AM PST, Google disabled the quota enforcement in one datacenter.
- By 04:27 AM PST, the same mitigation was applied to all datacenters.
- At 04:32 AM PST, error rates returned to normal levels, and all affected services were restored.
Lessons learned:
- Improve change management processes and safeguards for critical systems.
- Enhance monitoring and alerting systems to detect and respond to issues more quickly.
- Implement better testing procedures for automated systems that manage critical infrastructure.
- Improve communication channels during outages, both internally and externally.
- Regularly audit and validate network configurations and access control lists (ACLs)
You can learn from the experiences of these global tech giants to better prepare for future incidents. This knowledge will help you respond more effectively, ensuring improved system reliability and enhanced customer satisfaction.
Future of incident management
Technology is growing fast, and your traditional incident management methods just won’t keep up. That’s where AI comes in. It’s stepping up to speed up responses, minimize errors, and help teams handle incidents more effectively. AI is reshaping how we handle incidents in real-time.
Here’s a quick look at the top trends driving this shift:
- Automated incident detection & response
AI systems can monitor vast amounts of data in real-time, automatically detecting anomalies and triggering responses without human intervention. This reduces the time it takes to identify and address incidents, leading to faster resolutions. - Predictive analytics for proactive management
With machine learning algorithms, AI can analyze historical incident data to predict potential future issues. By spotting patterns early, AI helps teams take action before a minor issue escalates into a major incident. - Smart incident prioritization
AI can assess the severity of incidents in real-time and automatically prioritize them based on impact. This ensures that critical incidents are addressed first, preventing downtime and customer dissatisfaction. - AI-Powered root cause analysis
Once an incident occurs, AI tools can quickly analyze logs, performance data, and system metrics to pinpoint the root cause. This speeds up troubleshooting and reduces the reliance on manual investigation, saving valuable time.
Intelligent automation of remediation
AI-driven systems can automate repetitive remediation tasks, such as restarting services, rolling back updates, or reallocating resources. This not only saves time but also reduces the risk of human error during incident recovery.
How do we handle incident management in UptimeRobot?
UptimeRobot is a leading uptime monitoring service that lets users monitor up to 50 websites for free, with checks every five minutes.
With over 7.5 million monitors used by more than 2.1 million users, UptimeRobot quickly alerts website owners of any downtime, helping prevent revenue loss. The platform offers various monitoring options, such as SSL certification and domain expiration, cron job monitoring, and keyword tracking.
Users can get instant alerts via SMS, email, and integrations with tools like Slack and Microsoft Teams. UptimeRobot also provides customizable status pages to keep customers informed during outages, ensuring transparency and reliability.
Here’s an overview of our incident management process:
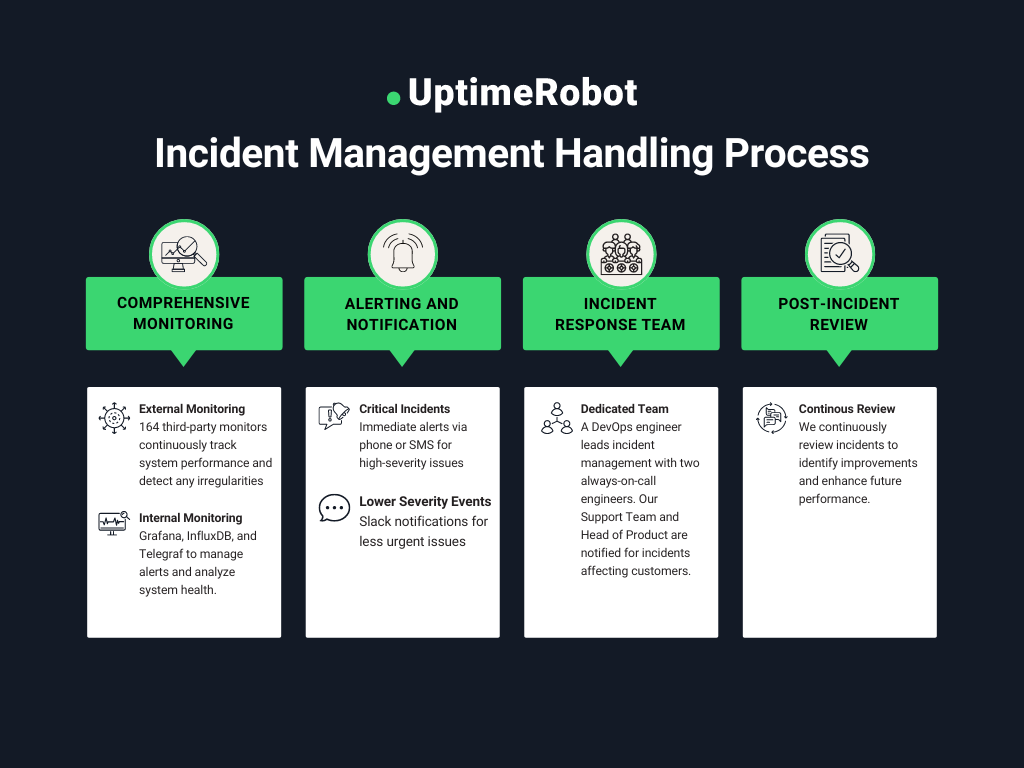
Comprehensive monitoring
- External monitoring: We deploy 164 third-party monitors to continuously oversee our systems, adding an extra layer of vigilance. These monitors detect any irregularities. We also use Cloudflare webhooks to receive alerts about DDoS attacks and issues with our load-balanced services, such as down heartbeat servers.
- Internal monitoring: We utilize Grafana, InfluxDB, and Telegraf for detailed system analytics and custom scripts tailored to our needs. PagerDuty handles critical alerts, while Slack manages less severe incidents.
Alerting and notification
We categorize our alerting methods based on the severity of the event.
- Critical incidents: For high-severity incidents, PagerDuty integrates with our monitoring tools to send immediate alerts via phone calls, SMS, or other channels.
- Lower-severity events: Less urgent issues are managed through Slack, ensuring efficient communication.
Incident response team
- Team structure: Our DevOps engineer leads incident management, supported by two additional engineers on an “always on-call” basis. For incidents affecting customers, we initiate restoration efforts and notify our Support Team and Head of Product for client communication.
Post-Incident Review
- Continuous improvement: After resolving an incident, we review the situation to identify improvements and update our backlog to enhance future performance.
This structured approach helps us effectively monitor, respond to, and learn from incidents, ensuring high service reliability and customer satisfaction.
Register for free with UptimeRobot today and take control of your monitoring needs. Start optimizing your incident management process now!
Incident management is a system, not a meeting
Incident management is often misunderstood as a checklist you follow during outages. In reality, it is a system of decisions made before, during, and after incidents to reduce impact and recovery time.
It starts with detection. An incident only exists once a signal requires human action. If alerts are noisy or unclear, teams hesitate. That delay is part of the incident. Good incident management depends on monitoring that people trust enough to act on immediately.
Once an incident is declared, ownership matters. One person should coordinate the response, even if many people are fixing things. Without a clear owner, communication fragments and decisions stall. This role is about flow, not heroics.
Communication is the next layer. Internally, responders need one shared place for updates, decisions, and status. Externally, users need clear, factual updates about impact and progress. Mixing these audiences creates confusion. Effective incident management separates them while keeping facts consistent.
Containment often matters more than speed. Many incidents get worse because changes continue while systems are unstable. Pausing deploys, freezing config changes, and limiting scope reduce blast radius. Fast action without guardrails increases risk.
Resolution is not the finish line. What happens next determines whether the same incident repeats. Post-incident reviews should focus on systems and process, not individuals. If reviews feel like blame sessions, people hide information and learning stops.
Over time, incident management reveals patterns. Repeated causes, slow detection, or unclear ownership point to structural gaps. The goal is not perfect uptime. It is fewer surprises and calmer responses when things break.
Good incident management feels boring. Alerts are clear. Roles are known. Updates follow a rhythm. Incidents end with concrete follow-ups instead of vague promises.
If incident response feels chaotic, the issue is rarely the outage itself. It is the system around it.
FAQ's
-
Incident management is the process of identifying, responding to, and resolving incidents that disrupt normal service operation. The primary goal is to restore service quickly while minimizing user impact. It also ensures incidents are handled consistently, not ad hoc.
-
An incident is any unplanned event that degrades or stops a service. This includes outages, severe performance issues, failed deployments, or broken integrations. If users are impacted, it’s usually an incident.
-
Incident management focuses on restoring service as fast as possible. Problem management looks for the underlying root cause and long-term fixes. Incident first, prevention second.
-
Responsibility usually falls on on-call engineers, SREs, or DevOps teams. Clear ownership and escalation paths are critical so incidents aren’t ignored or delayed. Well-defined roles reduce confusion under pressure.
-
Common reasons include alert fatigue, unclear ownership, poor documentation, or untested processes. Many failures are procedural rather than technical. A good incident process reduces human error during stressful situations.