In industries where system reliability and uptime are non-negotiable, understanding key metrics like MTTR can be the difference between smooth operations and costly downtime. MTTR, short for Mean Time to Repair, Recovery, Respond, or Resolve, depending on the situation, is a pillar of effective incident management.

These metrics help teams measure how efficiently they respond to and recover from issues, whether it’s a server outage, a broken piece of equipment, or a cybersecurity threat.
For software developers, facility managers, and IT professionals alike, MTTR provides actionable insights that drive performance improvements.
We’ll break down the different types of MTTR, why they matter, and how you can use them to cut downtime, streamline processes, and boost customer satisfaction. By the end, you’ll see how tracking and optimizing MTTR can elevate your incident management game.
What is MTTR?
MTTR is used in incident management and maintenance to measure the efficiency of your response and resolution efforts. However, MTTR has multiple variations, each focusing on a different aspect of incident management:
- Mean Time to Repair: Measures the average time taken to fix a failed system or component.
- Mean Time to Recovery: Tracks the time it takes to recover a system or service from downtime.
- Mean Time to Respond: Focuses on the time taken for teams to begin responding to an incident after detection.
- Mean Time to Resolve: Calculates the time required to fully resolve an incident from start to finish.
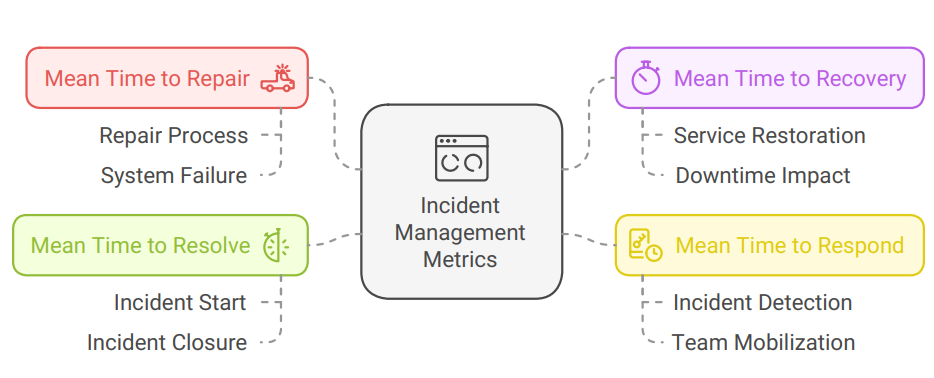
Each variation of MTTR serves a distinct purpose, giving teams a more granular view of their incident management performance.
Understanding the differences between these metrics means organizations can identify specific areas for improvement, whether that’s speeding up response times, improving repair efficiency, or streamlining recovery processes.
Tracking these metrics allows teams to:
- Discover and resolve bottlenecks in their workflows.
- Compare performance across teams or departments.
- Set realistic benchmarks and improvement goals tailored to their specific needs.
Ultimately, these metrics aren’t just for measuring time, they’re aptly suited for driving continuous improvement and learning more about how to prevent future incidents.
With the right MTTR data, teams can create strategies to reduce downtime, guarantee system reliability, and deliver a better experience for end users.
Why MTTR matters
Each variation of MTTR – whether it’s Repair, Recovery, Respond, or Resolve – offers unique information about different stages of the incident management lifecycle.
Together, they provide a comprehensive picture of your team’s ability to handle issues efficiently, highlighting areas for improvement and strategies to optimize processes.
- Customer satisfaction: Faster resolutions build trust and ensure customers aren’t left waiting.
- Resource optimization: Understanding MTTR helps allocate resources to high-priority tasks.
- Continuous improvement: Regularly tracking MTTR metrics identifies bottlenecks and inefficiencies.
Tracking and improving MTTR doesn’t just streamline operations, it gives your team the agility needed to adapt to challenges and maintain peak performance.
Mean Time to Recovery
When systems fail, every second counts. Mean Time to Recovery is the metric that goes beyond simply fixing the problem, and evaluates how quickly an organization can restore full functionality after a disruption.
This metric is particularly important in environments where uptime directly impacts customer satisfaction, productivity, or even safety.
What is Mean Time to Recovery?
Mean Time to Recovery measures the average time it takes to restore a system, service, or component to full functionality after a failure or downtime event.
Unlike the general MTTR, which may focus on repair time alone, Mean Time to Recovery emphasizes the entire process of bringing the system back online and operational.
For example, in IT systems, this could mean recovering from a server crash, while in manufacturing, it could involve restarting a production line after a mechanical failure.
Why Mean Time to Recovery matters
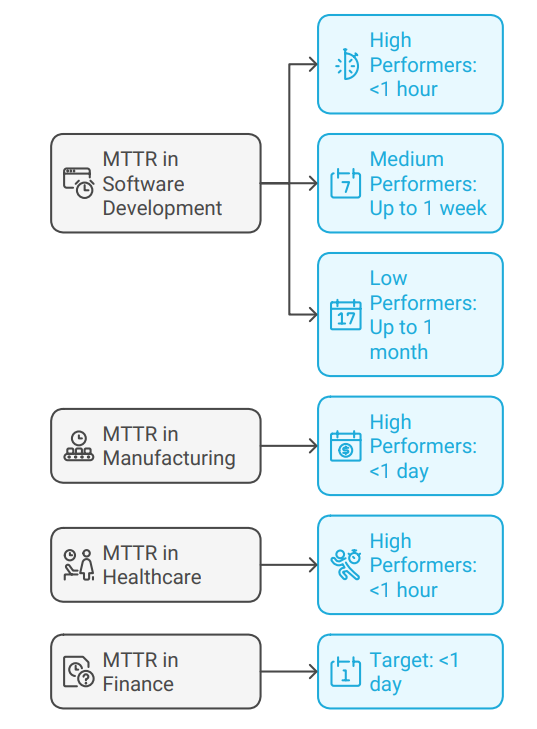
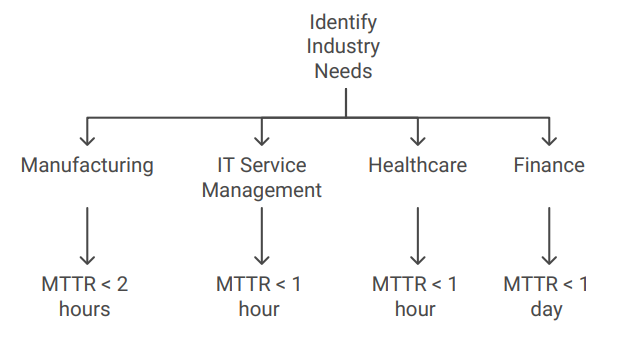
Mean Time to Recovery is best used in industries where high availability is essential, such as healthcare, banking, and telecommunications. Here’s why it’s important:
- Minimizes downtime: Faster recovery means less time lost to outages and disruptions.
- Builds customer trust: Rapid recovery helps maintain customer confidence in your service or product.
- Protects revenue: Reduced downtime can prevent major financial losses, especially in industries where every minute matters.
For example, in banking, an ATM network outage during peak hours can disrupt thousands of transactions, leading to frustrated customers and potential revenue loss.
In this situation, a low MTTR means that systems are restored quickly, allowing customers to use the ATM with little to no disruption, and retaining customer satisfaction.
How to calculate Mean Time to Recovery
The formula for calculating MTTR (Recovery) is straightforward:
MTTR (Recovery) = Total Downtime / Number of Recovery Incidents
Let’s do an example calculation:
- Total Downtime: 10 hours
- Number of Recovery Incidents: 5
MTTR (Recovery) = 10 hours / 5 = 2 hours
This means the average recovery time for each incident is 2 hours.
When & why to use Mean Time to Recovery
Tracking Mean Time to Recovery is particularly valuable in industries with critical infrastructure or high uptime demands, such as:
- Telecommunications: Ensuring rapid recovery of network outages.
- E-commerce: Restoring online storefronts during peak shopping hours.
- Manufacturing: Minimizing downtime on production lines.
Mean Time to Respond
In incident management, the speed of your initial response can often determine the overall impact of an issue.
Mean Time to Respond (MTTR) focuses on the window between detecting a problem and beginning to address it. Quick reaction times are essential for mitigating risks, stopping issues from escalating, and keeping operations stable – making this metric a key indicator of response efficiency.
What is Mean Time to Respond?
Mean Time to Respond measures the average time it takes for a team to begin responding to an incident after it’s detected. Unlike Mean Time to Repair or Mean Time to Recover, which focus on resolution and recovery, this metric emphasizes the initial reaction time to an issue.
For example, in IT, this could mean the time between when an alert is generated for a server issue and when a technician starts investigating it.
Why Mean Time to Respond matters
Mean Time to Respond is a key indicator of a team’s readiness and responsiveness. Here’s why it’s important:
- Prevents escalation: Faster responses can stop an issue from turning into a major problem.
- Mitigates damage: Quick action can reduce the impact of an incident, whether it’s a security breach or a critical system failure.
- Improves customer confidence: A prompt response shows customers that their concerns are taken seriously.
In cybersecurity, consider a scenario where a potential data breach is detected on a company’s network. If the response team takes hours to act, the attacker would have ample time to extract sensitive customer information, such as credit card details or personal data.
On the other hand, a low Mean Time to Respond measured in minutes rather than hours could allow the team to isolate the affected systems, block the attacker, and secure the data before significant harm is done.
Such a swift response minimizes the breach’s impact, protects the company’s reputation, and prevents legal or financial repercussions.
How to calculate Mean Time to Respond
The formula for MTTR (Respond) is:
MTTR (Respond) = Total Response Time / Number of Incidents
Here is a simple example:
- Total Response Time: 15 hours
- Number of Incidents: 5
- MTTR (Respond) = 15 hours / 5 = 3 hours
Here, the average response time for incidents is 3 hours.
When & why to use Mean Time to Respond
Mean Time to Respond is valuable in scenarios where a quick initial reaction is extremely important, such as:
- Cybersecurity: Responding to breaches or attacks before they cause widespread damage.
- Facility management: Addressing issues like power outages or HVAC failures promptly.
- IT operations: Reacting to network disruptions to maintain uptime.
Mean Time to Repair
When systems or equipment fail, restoring functionality quickly is essential to minimize disruption.
Mean Time to Repair focuses on the efficiency of the repair process itself, providing a clear picture of how well teams can restore operations.
This metric provides insight into repair times, revealing opportunities to streamline processes, reduce delays, and maintain productivity.
What is Mean Time to Repair?
Mean Time to Repair measures the average time it takes to repair a system, component, or piece of equipment after a failure occurs. It focuses specifically on the repair phase, excluding the time it takes to detect or respond to the issue.
For example, in manufacturing, this could mean the time required to fix a conveyor belt, while in IT, it might refer to restoring a malfunctioning server.
Why Mean Time to Repair matters
Reducing Mean Time to Repair is necessary in industries where downtime directly impacts productivity and revenue.
- Minimizes operational disruptions: Faster repairs mean less time lost to downtime.
- Improves equipment availability: Short repair times increase the uptime of critical assets.
- Boosts customer satisfaction: For customer-facing systems, quick repairs prevent prolonged service disruptions.
For example, let’s imagine a manufacturing production line experiences a mechanical failure during peak operation hours. Every hour of downtime results in significant losses, not just in terms of production delays, but also unfulfilled orders, frustrated clients, and overtime costs for staff attempting to catch up.
With a low Mean Time to Repair, the issue can be quickly diagnosed and resolved, allowing the production line to resume operations with minimal disruption. Having a low MTTR here not only protects revenue, but also maintains the trust of clients relying on on-time deliveries.
How to calculate Mean Time to Repair
The formula for MTTR (Repair) is:
MTTR (Repair) = Total Repair Time / Number of Repairs
For example:
- Total Repair Time: 20 hours
- Number of Repairs: 10
MTTR (Repair) = 20 hours / 10 = 2 hours
In this situation, the average time to repair a failure is 2 hours.
When & why to use Mean Time to Repair
MTTR is especially useful in asset-heavy industries where equipment reliability is essential. Some common use cases include:
- Manufacturing: Tracking repair times for production machinery to ensure seamless operations.
- Facility management: Monitoring repair times for infrastructure like elevators or HVAC systems.
- IT systems: Measuring repair efficiency for hardware or software components.
Monitoring Mean Time to Repair lets businesses spot delays in their repair processes, prioritize resources where they’re needed most, and find ways to cut downtime and expenses.
Mean Time to Resolve
Making sure that incidents are fully resolved, rather than just temporarily fixed, is essential for long-term operational stability. Mean Time to Resolve focuses on the entire lifecycle of an incident, capturing the time from its initial detection to complete resolution.
This metric provides a full and complete view of incident management performance, helping organizations ensure issues are addressed thoroughly and effectively, rather than reoccurring down the line.
What is Mean Time to Resolve?
Mean Time to Resolve measures the average time it takes to fully resolve an incident, from the moment it is detected to its complete resolution. This metric includes every stage of the incident lifecycle, such as detection, response, repair, recovery, and verification.
As an example, resolving a bug in the software world might involve identifying the issue, developing and deploying a fix, and verifying that the problem no longer exists.
Why Mean Time to Resolve matters
Mean Time to Resolve is helpful for understanding the overall efficiency of incident management processes. It’s important to use for these reasons:
- Comprehensive incident management: It provides a holistic view of how quickly teams can identify, address, and fully resolve issues.
- Improved customer satisfaction: Swift resolution times reduce the impact on customers, enhancing their trust in your service or product.
- Better operational efficiency: A shorter resolution time minimizes disruptions and allows teams to focus on other priorities.
To help visualize a real use case, imagine a major e-commerce platform experiencing a payment processing error during a holiday shopping rush. Customers are unable to complete purchases, which leads to frustration and abandoned carts.
A high Mean Time to Resolve could mean hours of lost sales, eroding customer trust and damaging the company’s reputation. However, with a low Mean Time to Resolve, the technical team identifies the root cause, deploys a fix, and verifies the system within minutes.
Quick action like this restores functionality, minimizes revenue loss, and reassures customers that their experience is a top priority.
How to calculate Mean Time to Resolve
The formula for MTTR (Resolve) is:
MTTR (Resolve) = Total Resolution Time / Number of Incidents
Here’s a quick calculation:
- Total Resolution Time: 50 hours
- Number of Incidents: 10
MTTR (Resolve) = 50 hours / 10 = 5 hours
This means it takes an average of 5 hours to fully resolve each incident.
When & why to use Mean Time to Resolve
Tracking Mean Time to Resolve is essential in industries where complete and timely resolution is paramount, such as:
- Software development: Addressing bugs and deploying fixes to maintain seamless user experiences.
- Healthcare IT: Ensuring rapid resolution of system failures that impact patient care.
- Customer support: Resolving customer issues to prevent churn and maintain satisfaction.
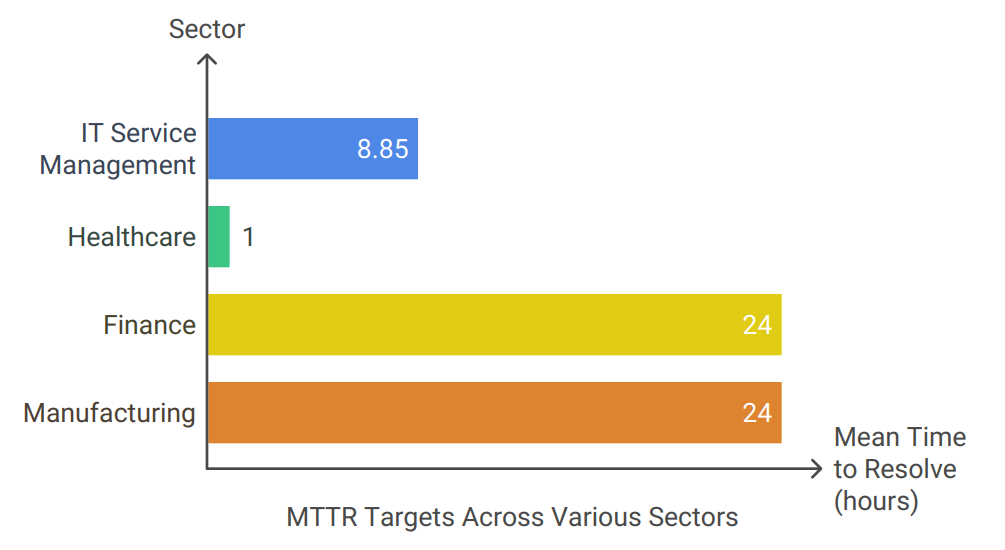
Tracking this metric enables organizations to pinpoint bottlenecks in their resolution processes, refine workflows for greater efficiency, and adopt best practices to consistently shorten resolution times.
Conclusion
Improving operational efficiency is a priority across industries, and MTTR metrics – whether it’s Mean Time to Recovery, Respond, Repair, or Resolve – offer valuable data about how teams manage incidents and maintain system reliability. Each variation highlights specific areas of improvement, empowering businesses to better understand their response and resolution capabilities.
When actively tracking and optimizing MTTR organizations can:
- Minimize expensive downtime and operational disruptions.
- Build trust and loyalty through faster issue resolution.
- Uncover inefficiencies and implement strategies to streamline processes.
From IT systems to manufacturing lines and many industries in between, focusing on MTTR metrics does more than just refining day-to-day operations – it creates a foundation for long-term success.
The ability to react quickly, recover effectively, and resolve completely gives businesses a distinct edge in competitive markets.
Now is the time to start measuring your MTTR. Choose the metrics most relevant to your goals, analyze the data, and refine your processes to achieve greater efficiency, resilience, and customer satisfaction.
Track & improve MTTR with UptimeRobot
Reducing MTTR starts with understanding it, but the real power lies in having the right tools to monitor and optimize your processes. UptimeRobot makes it easy to track downtime, detect issues early, and superchrage your response efforts.
With real-time monitoring, instant alerts, and custom status pages, UptimeRobot gives your team the insights they need to minimize disruptions and improve efficiency.
No matter if you’re managing IT systems, websites, or critical infrastructure, UptimeRobot helps you stay one step ahead and keep your systems running smoothly.
Take control of your MTTR today with UptimeRobot.