Artificial intelligence (AI) is showing up everywhere. That means you’re either someone who has already adopted AI in your business or you’re planning to implement it soon. In either case, building and deploying AI models is only the beginning. You need to monitor AI systems continuously to keep them running smoothly and delivering value.
AI monitoring helps teams track performance, catch issues early, manage costs, and ensure systems stay compliant and aligned with business goals. Without it, even the best AI models can drift, break, or behave unpredictably.
In this article, we’ll walk through what AI monitoring is, how it works, common challenges, best practices, and how you can set it up for success.
Key takeaways:
- AI monitoring means continuously tracking the performance, behavior, and reliability of AI systems in production. It helps teams catch issues like model drift, latency spikes, and data quality problems before they affect users or business outcomes.
- Don’t monitor everything—monitor what matters. Focus on metrics like inference latency, accuracy, throughput, and resource utilization. These directly impact user experience and model effectiveness.
- Effective AI monitoring starts with solid observability. Use tools that collect metrics, logs, and traces across your entire system to pinpoint issues quickly and understand root causes.
- Monitor access, encrypt data in transit, and follow privacy regulations—especially in sensitive fields like healthcare and finance.
- Use dynamic thresholds, group related alerts, and set clear escalation rules. This reduces noise and helps your team respond faster to real issues.
What is AI monitoring?
AI monitoring is like application performance monitoring (APM), but for AI systems. It focuses on continuously tracking how models perform once they’re live. Teams use it to watch metrics like accuracy, latency, data drift, model drift, and uptime. This helps them spot issues early, fix them quickly, reduce risk, control costs, and keep AI systems running reliably.
What is AI monitoring vs. traditional monitoring?
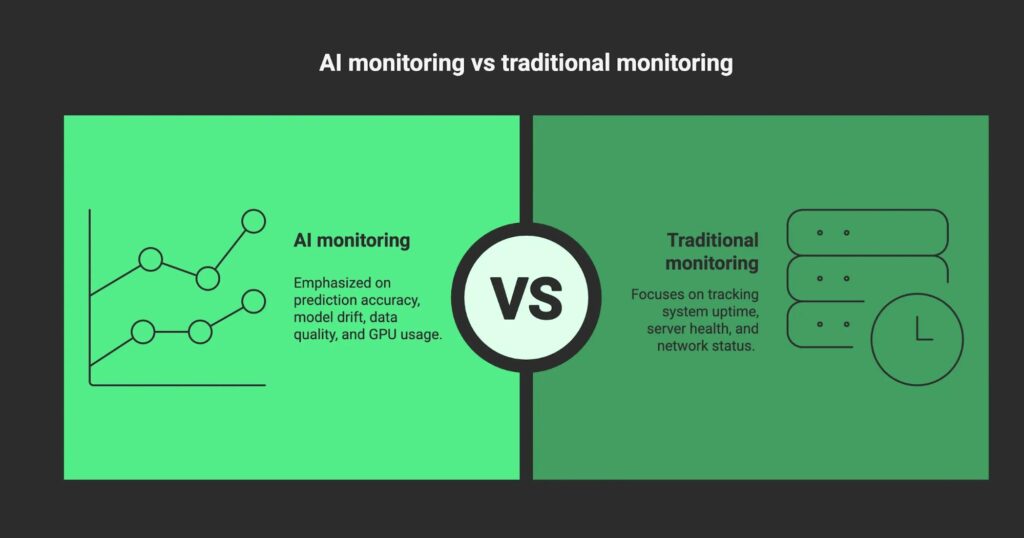
Your AI systems need a different kind of monitoring compared to traditional software. Traditional monitoring focuses on things like uptime, server health, and error rates. While these still matter for AI systems, you also need to track metrics such as prediction accuracy, model drift, data quality, and GPU usage.
Let’s understand this with an example:
Imagine you run an e-commerce business. Traditional monitoring would tell you if your site is up, how fast it loads, and whether any backend services are failing. But if you use an AI-powered recommendation engine, traditional monitoring alone won’t show whether the model suggests the right products.
Imagine customer preferences changing due to a seasonal event or a sudden trend. If incoming data shifts slightly, like more searches for “winter jackets”, and your AI model wasn’t trained for that change, it might still recommend summer clothes.
The system runs fine technically, but the AI underperforms. That’s where AI monitoring helps. It alerts your team to drops in recommendation accuracy or detects data drift, so you can retrain or adjust the model before it hurts sales.
AI workloads depend heavily on high-quality input and are more sensitive to data changes. Even small shifts in data can cause AI models to behave unpredictably. This makes AI monitoring both more complex and more critical than traditional monitoring.
Why is AI monitoring becoming a critical requirement?
A recent McKinsey survey shows that 78% of organizations now use AI in at least one business function, up from 72% earlier in 2024. AI adoption continues to grow across industries.
Hospitals use AI to support diagnostics and patient monitoring. Financial institutions rely on AI to detect fraud and assess risk. Even customer service teams depend on AI-powered chatbots to handle thousands of inquiries every day.
As AI takes on bigger roles, the cost of errors increases. A small drop in model performance or unnoticed shifts in data can lead to incorrect medical diagnoses, missed fraud detection, poor customer experiences, lost revenue, or compliance breaches. These impacts affect both people’s lives and business results.
That’s why AI monitoring has become essential. It provides teams with real-time insights into how AI models perform in production. Monitoring helps detect performance drops, data drift, or system issues early, before they escalate into major problems.
Where AI monitoring helps and where it still falls short
AI monitoring is often framed as a replacement for traditional alerts. In practice, it works best as a layer on top of existing signals, not a substitute for them.
The main strength of AI-driven monitoring is pattern detection. Instead of relying on fixed thresholds, these systems learn what “normal” looks like and flag deviations. This is useful for dynamic environments where traffic, load, or usage changes constantly and static rules create noise.
Anomaly detection shines with gradual problems. Memory leaks, slow latency creep, or unusual traffic patterns are hard to catch with simple alerts. AI models can spot these shifts earlier because they look at trends and relationships across metrics, not single values.
AI also helps with correlation. During incidents, many alerts fire at once. AI-based systems can group related signals and highlight likely root causes. This reduces alert floods and helps responders focus on what changed first, not what broke last.
That said, AI monitoring has limits. It still depends on good data. If metrics are missing, mislabeled, or noisy, the output will be unreliable. AI does not fix poor instrumentation. It amplifies whatever you feed into it.
Explainability is another gap. When a threshold alert fires, the reason is obvious. When an AI system flags an anomaly, the “why” can be unclear. Teams need enough transparency to trust alerts during incidents, not second-guess them.
AI also struggles with rare but valid events. Planned traffic spikes, migrations, or one-off jobs can look anomalous even when everything is fine. Without context, AI flags expected behavior as problems. Human awareness still matters.
Most teams get the best results with a hybrid approach. Use traditional monitoring for clear failures like downtime, errors, and missed jobs. Use AI monitoring to surface subtle changes and reduce noise across large metric sets.
The goal is not fewer alerts at any cost. It is faster understanding when something unusual happens.
AI monitoring works when it supports human judgment, not when it tries to replace it.
Pillars of effective AI monitoring
Building a strong AI monitoring system relies on two key pillars: comprehensive observability and a balanced approach to real-time and historical monitoring.
Observability components: Metrics, logs, traces
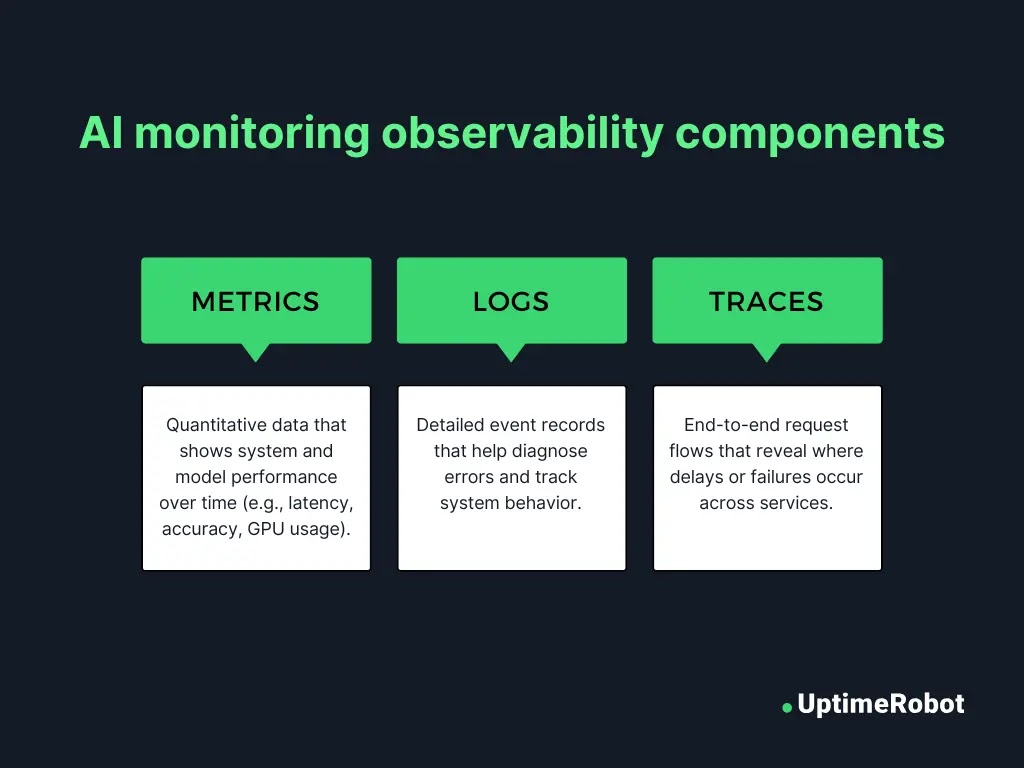
Effective AI monitoring starts with solid observability. Teams must track model-specific metrics such as inference latency (how fast the model responds), prediction accuracy, and GPU usage, since AI workloads often depend on heavy computation. Alongside these, standard infrastructure metrics like CPU load, memory consumption, and network performance provide essential context about the environment hosting the AI system.
Logs capture detailed records of system events, while traces map the flow of requests through different services. Together, they help teams understand how the system behaves and quickly pinpoint the root cause when issues arise.
Real-time vs. historical monitoring
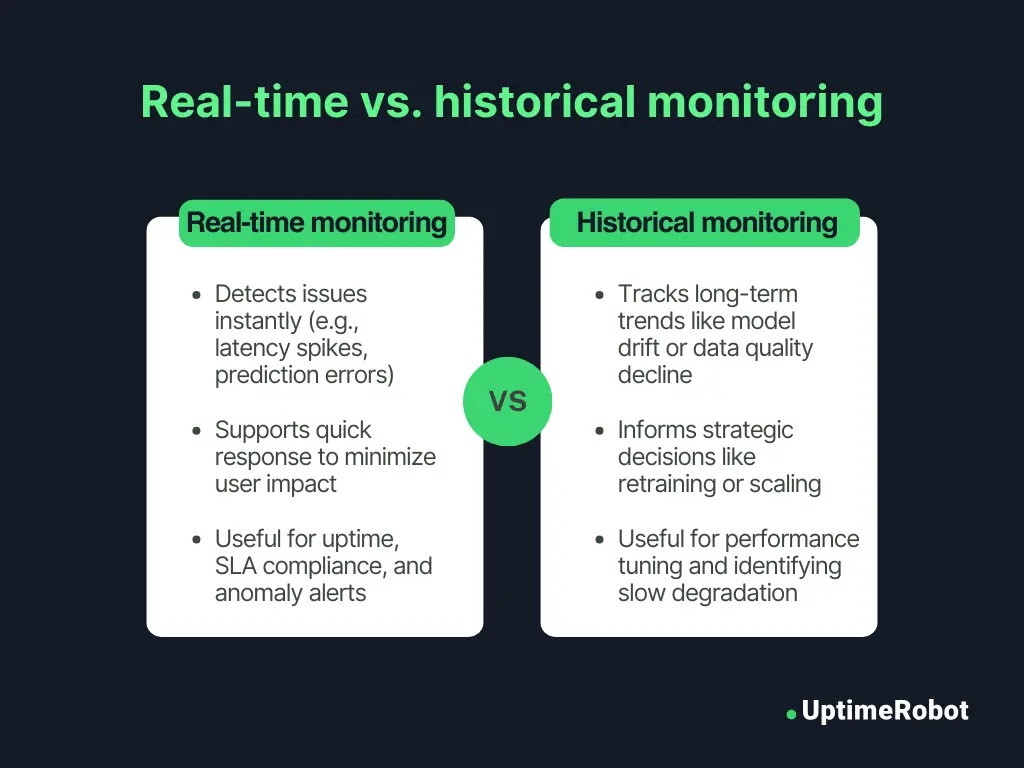
AI monitoring needs both real-time and historical perspectives to work well. Real-time monitoring sends instant alerts for issues like latency spikes, prediction errors, or outages. This lets teams act fast and reduce impact.
Historical monitoring tracks performance over longer periods. It catches slow problems like model drift, where accuracy drops due to changing data patterns. It also spots gradual declines in data quality.
Analysing these trends helps teams plan model retraining, tuning, or infrastructure scaling to maintain reliability and alignment with business goals.
Common challenges & solutions in AI monitoring
AI monitoring is essential, but it also brings unique challenges. Overcoming these is necessary to ensure your systems stay reliable and perform well. Below are some common challenges and how to address them.
Data pipeline complexity
AI workflows include multiple stages – data ingestion, preprocessing, model inference, and post-processing. Each stage relies on the previous one working properly. A failure in one stage can ripple through the entire process. This makes troubleshooting difficult, as teams must trace issues step-by-step to identify the root cause.
The solution here would be to set up end-to-end observability across your pipeline. Use tools like OpenTelemetry to trace requests through each stage. You can also monitor key metrics and logs at every step to quickly find the root cause of issues, and add data validation early to catch corrupted or missing data before it impacts model performance.
Model behavior under real-world conditions
AI models train on historical data, but real-world inputs often differ. For instance, a financial AI model trained on data from stable market conditions may struggle during sudden market crashes or unexpected economic events. These unusual inputs can cause the model to make inaccurate risk assessments or generate false fraud alerts.
To combat this, track model performance against live data, use monitoring tools to compare real-time inputs with training data (data drift detection), and monitor key metrics like accuracy or precision.
Set thresholds to trigger retraining or flag issues when performance drops, and consider shadow testing with live traffic before rolling out updates.
Alert fatigue
AI systems produce large volumes of logs, metrics, and events. Without carefully tuned alert thresholds and effective anomaly detection, teams can get overwhelmed by too many notifications, many of which may be false alarms or low-priority issues. This flood of alerts can lead teams to overlook or miss critical warnings.
Use smart alerting to reduce noise and focus on what matters. Set dynamic thresholds based on baselines instead of fixed numbers, and group similar alerts (deduplication) and define escalation paths for critical issues. Regularly review alert rules and train your team on runbooks to speed up incident response.
Implementing an AI monitoring stack
To build a reliable AI monitoring system, you need more than just tools – you need a strategy that connects the right metrics, integrates with your workflows, and keeps data secure. Here’s how to set it up:
1. Selecting tools and integrations
Start by choosing monitoring tools that align with your existing infrastructure. Look for solutions that support both AI-specific metrics and traditional infrastructure observability.
For example, you can use UptimeRobot to monitor critical AI endpoints and combine it with OpenTelemetry or Grafana to visualize model performance alongside system health.
2. Setting up metrics that matter
Don’t track everything. Focus on the metrics that directly impact your model’s outcomes and the end-user experience. Monitoring too many signals can create noise and distract from what really matters.
Here are four essential metrics to monitor:
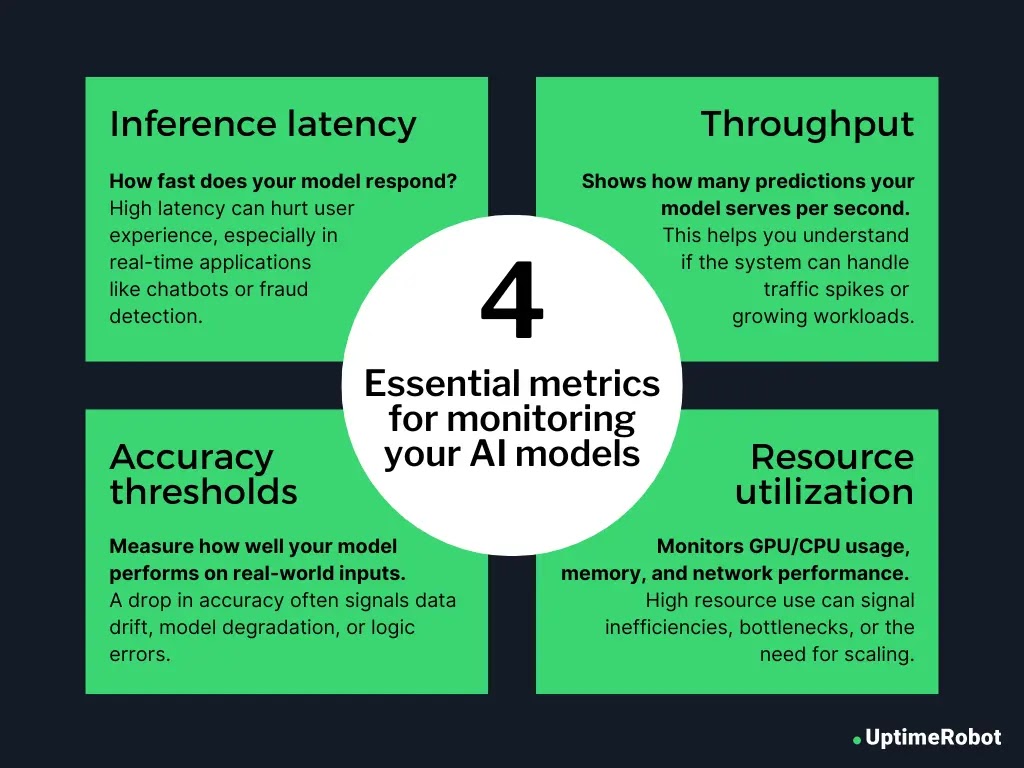
- Inference latency
How fast does your model respond? High latency can hurt user experience, especially in real-time applications like chatbots or fraud detection. - Accuracy thresholds
Measure how well your model performs on real-world inputs. A drop in accuracy often signals data drift, model degradation, or logic errors. - Throughput
Shows how many predictions your model serves per second or minute. This helps you understand if the system can handle traffic spikes or growing workloads. - Resource utilization
Monitors GPU/CPU usage, memory, and network performance. High resource use can signal inefficiencies, bottlenecks, or the need for scaling.
Pro tip: Define alert thresholds for each metric. For example, trigger an alert if latency goes above 500ms or if accuracy drops below 90%. Add these rules to your monitoring configuration so your team can act fast when something goes off track.
3. Securing your AI monitoring
Monitoring systems often handle sensitive data, including logs, traces, and prediction results. If left unsecured, these systems can become an attack vector or lead to data privacy violations.
Here’s how to secure them:
- Enforce strong authentication
Restrict access to dashboards, APIs, and logs using secure login methods like OAuth, SSO, or API tokens. Avoid default credentials or open endpoints. - Encrypt data in transit
Always use HTTPS and TLS to protect monitoring data as it moves across networks. This prevents interception or tampering during transmission. - Apply role-based access control (RBAC)
Not everyone needs full access. Use RBAC to limit visibility and permissions based on team roles. - Anonymize sensitive data
Logs and traces may contain personally identifiable information (PII). Mask or anonymize sensitive fields to comply with regulations like GDPR, HIPAA, or CCPA.
Actionable best practices
Monitoring data alone won’t protect your AI systems. These best practices show how to turn insights into action, helping teams respond faster, cut costs, and improve model reliability.
Proactive alerting and incident response
Be prepared before things go wrong. Create clear, step-by-step runbooks for handling common AI incidents. For instance, if inference errors spike suddenly, the runbook should prompt teams to first check for recent data schema changes, input anomalies, or signs of model drift.
Use alerting tools like PagerDuty or Opsgenie to route alerts across multiple channels:
- Slack for immediate collaboration
- Email for audit trails
- SMS for after-hours emergencies
Define escalation policies to ensure unresolved alerts are automatically passed to senior team members within a defined timeframe.
Pro tip: Run regular drills to test your alerting setup. This reduces alert fatigue and ensures critical issues don’t get lost in the noise.
Performance optimization and cost control
AI systems can use a lot of computing power. Tasks like real-time predictions often require heavy GPU or CPU usage. This makes it important to monitor performance and cost closely.
For example, if your model gets slower during busy hours, it might be running out of resources. You can fix this by adding more compute power when needed or using a smaller, faster version of the model during peak times.
Monitoring also helps you spot resource waste. Your system might keep GPU instances running even when the model is idle. In that case, you may need to adjust your autoscaling settings or choose more efficient server types.
Pro tip: Connect your monitoring tools with autoscaling rules. This lets your system respond to demand automatically. You save money when usage drops and stay fast when traffic increases.
Continuous improvement and model updates
Monitoring is not just for spotting problems. It also helps teams improve models over time. If you notice a small drop in accuracy over a few weeks, it may be a sign that your model needs retraining. New data, user behavior, or external changes can affect model performance.
When updating a model, avoid pushing changes to all users at once. Use A/B testing to compare versions, or try canary deployments to release updates to a small group first. Watch performance closely before a full rollout.
Pro tip: Set up automatic triggers for retraining or rollback. If accuracy drops or latency increases beyond your set limits, the system should respond on its own. This keeps your models reliable with less manual work.
Real-world use cases
AI monitoring ensures that AI systems deliver reliable, accurate, and safe results in critical industries. Here are examples showing the impact of effective AI monitoring.
Industry examples
AI monitoring maintains trust and performance across various sectors by catching issues early and enabling timely interventions.
Personalization models in e-commerce
An e-commerce platform continuously monitors its AI-powered recommendation engine to ensure product suggestions remain relevant and timely. By tracking metrics like click-through rates, conversion rates, and model response times, the team can quickly spot drops in engagement.
When holiday traffic introduced unexpected product trends, monitoring surfaced a mismatch between user intent and recommendations. The team retrained the model to align with new patterns. This improved relevance and boosted sales.
Predictive risk models in healthcare
A healthcare provider uses AI to predict patient readmission risks. To maintain accuracy, the provider monitors key performance indicators such as prediction precision, recall, and data quality.
When a shift in patient demographics caused the model’s accuracy to decline, real-time monitoring flagged the issue. This enabled the team to retrain the model with updated data and restore its predictive performance, helping clinicians better allocate care resources.
Fraud detection system in finance
A financial services company continuously monitors its AI models used for fraud detection, especially during periods when more customers are looking to get a loan. The team tracks false positives, detection accuracy, and changes in transaction behavior.
During a spike in online payments, the system flagged a rise in false alerts linked to changing customer purchase patterns. Monitoring allowed rapid adaptation, ensuring fraud detection remained effective while minimizing disruption for legitimate users.
Success stories
These real-world success stories highlight the impact of effective AI monitoring.
1. Netflix: Monitoring recommendation models
Netflix relies heavily on machine learning to power its personalized recommendation system, which influences what users watch. However, user behavior and content libraries are constantly changing, which can cause the models to become less effective over time.
To handle this, Netflix implements model monitoring and drift detection practices. They track changes in input data distributions (feature drift), model outputs (prediction drift), and user engagement metrics (like click-through rate). Their systems can flag when the current model starts to deviate from expected behavior.
For example, if a recommendation model begins showing content that users skip or ignore, it triggers an internal review. Netflix uses statistical techniques and internal tools to monitor this performance in real time, allowing teams to retrain models or adjust algorithms before the user experience is affected.
2. LinkedIn: AlerTiger for real-time model health monitoring
LinkedIn created an internal AI monitoring tool called AlerTiger to track the health of machine learning models running in production. These models power key features like People You May Know, job recommendations, and feed ranking.
AlerTiger continuously monitors input features, model predictions, and system metrics. It uses a deep learning model to learn “normal” behavior patterns and then identifies anomalies such as unusual spikes in feature values, shifts in prediction scores, or degraded latency.
The system sends automated alerts to the ML engineering teams when it detects issues, helping them investigate potential data drift, label mismatches, or infrastructure failures. This proactive approach helps LinkedIn’s models stay performant and reliable, even as user behavior and data evolve.
3. Nubank: Proactive monitoring for financial ML models
Nubank, a leading digital bank in Latin America, has implemented proactive monitoring strategies for its machine learning models, particularly those involved in credit risk assessment and fraud detection.
By continuously tracking model performance metrics and data drift, Nubank ensures that its models remain accurate and reliable in the face of changing financial behaviors and market conditions.
This vigilant monitoring allows for timely interventions, such as model retraining or adjustment, thereby maintaining the integrity of their financial services and safeguarding customer trust.
Next steps for implementing AI monitoring
If you’re already running AI models in production or planning to deploy them soon, now is the time to assess your monitoring strategy.
- Identify your AI workloads: Start by listing the AI models and systems you have in production or plan to deploy. Understand their purpose and how critical they are to your business outcomes.
- Define key metrics: Decide which performance indicators matter most. Common metrics include model accuracy, prediction latency, throughput, and resource usage. Focus on what impacts user experience and business goals.
- Set up an AI monitoring kit: Choose monitoring tools that fit your tech stack and can track your key metrics. Integrate alerts and dashboards to get real-time insights and respond quickly to issues.
Following these steps keeps your AI models accurate, reliable, and aligned with your business goals as they evolve.
How UptimeRobot supports AI monitoring
UptimeRobot helps you keep a close eye on the health of your AI systems byregularly checking critical endpoints such as APIs, web interfaces, or model prediction services. These checks happen at set intervals, ensuring that your AI infrastructure is always under watch.
If an endpoint becomes unreachable, responds too slowly, or returns errors, UptimeRobot sends instant alerts to your team through channels like Slack, email, or SMS. This immediate notification helps you react quickly to issues before they affect users or business outcomes.
Beyond basic uptime checks, UptimeRobot integrates smoothly with popular observability tools like Grafana and OpenTelemetry. This allows you to combine AI-specific monitoring data with your overall system metrics, providing a unified, flexible view of your infrastructure’s health and performance.
Conclusion
AI adoption will continue to grow rapidly over the next few years. So, how can you make ure your AI systems keep pace? AI monitoring is the answer. It helps you tackle crucial questions about your AI applications: Are users waiting too long for responses? Is there a sudden spike in token usage? Are there trends in negative user feedback on specific topics?
By catching issues early and tracking performance trends, AI monitoring keeps your systems aligned with real-world conditions. With the right tools and processes in place, you’ll have the confidence to deploy AI in the most critical areas of your business safely and effectively.
FAQ's
-
AI monitoring uses machine learning models to detect anomalies, patterns, or abnormal behavior in systems and metrics. Instead of fixed thresholds, it learns what “normal” looks like over time. This helps catch issues that static rules often miss.
-
Traditional monitoring relies on predefined thresholds and rules. AI monitoring adapts automatically as traffic patterns, workloads, or usage change. This reduces manual tuning and improves detection of subtle or unexpected issues.
-
AI monitoring can detect anomalies like unusual latency spikes, traffic drops, error rate changes, or resource usage patterns. It’s especially useful for identifying gradual degradation and intermittent issues. These are often hard to catch with simple thresholds.
-
No, it complements them. Static thresholds are still useful for known failure conditions. AI monitoring adds an extra layer for detecting unknown or evolving problems.
-
AI monitoring works best with historical data to establish baselines. With limited data, accuracy may be lower until patterns are learned. Most systems improve automatically as more data is collected.